同步问题:step1-2-3
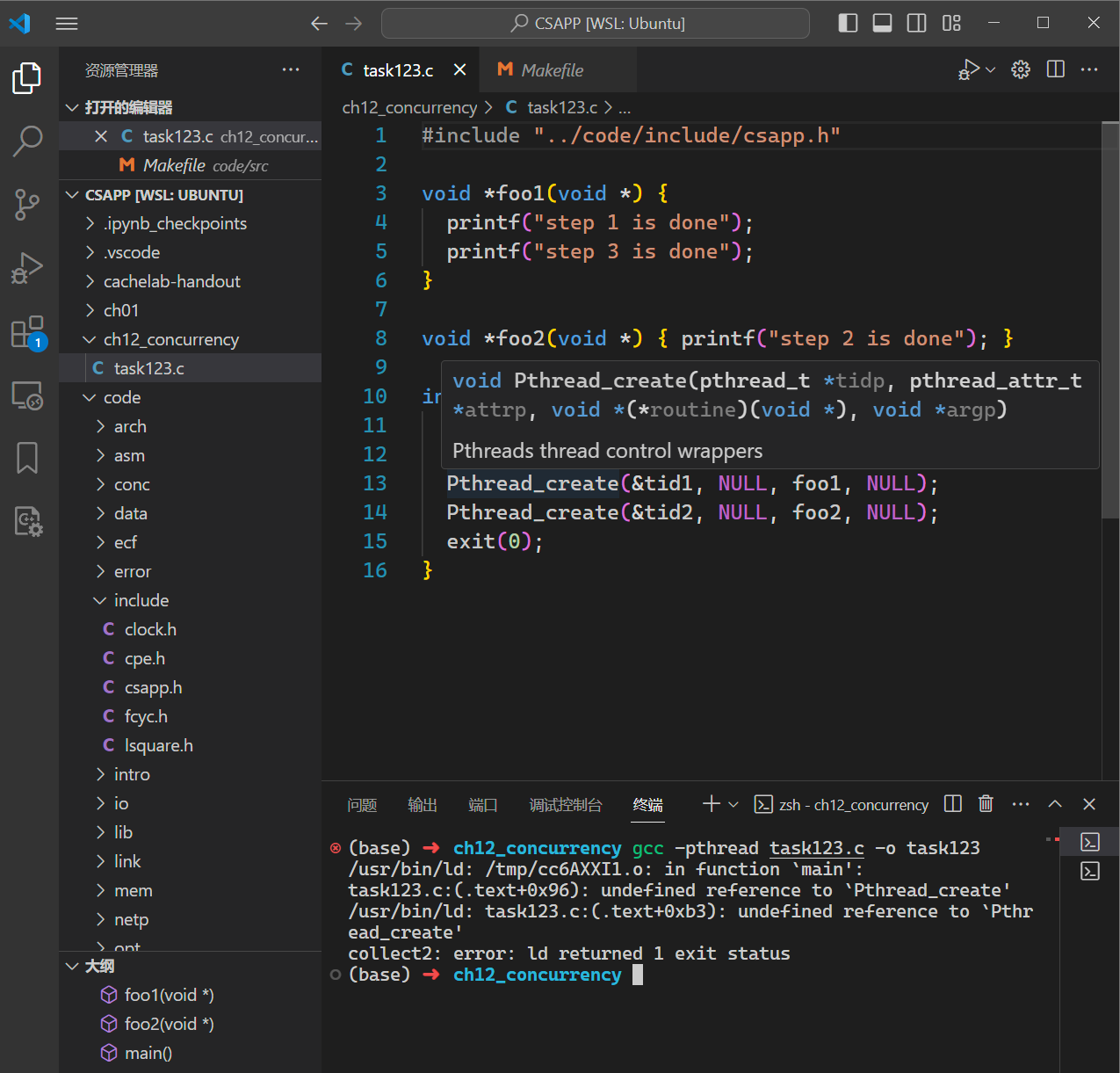
Q: 对于如下的代码,如何使得 foo1 的 step1 和 step2 以及 foo2 中的 step3 按照 step1、2、3 的顺序执行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void *foo1 (void *) { printf ("step 1 is done\n" ); printf ("step 3 is done\n" ); } void *foo2 (void *) { printf ("step 2 is done\n" ); }int main () { pthread_t tid1; pthread_t tid2; Pthread_create(&tid1, NULL , foo1, NULL ); Pthread_create(&tid2, NULL , foo2, NULL ); Pthread_join(tid1, NULL ); Pthread_join(tid2, NULL ); exit (0 ); }
这是一个经典的同步问题,下面提供 C (便于简洁地描述原理)和 C++ 两种方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #include "../code/include/csapp.h" sem_t step1_done, step2_done;void *foo1 (void *) { printf ("step 1 is done\n" ); V(&step1_done); P(&step2_done); printf ("step 3 is done\n" ); } void *foo2 (void *) { P(&step1_done); printf ("step 2 is done\n" ); V(&step2_done); } int main () { pthread_t tid1, tid2; Sem_init(&step1_done, 0 , 0 ); Sem_init(&step2_done, 0 , 0 ); Pthread_create(&tid1, NULL , foo1, NULL ); Pthread_create(&tid2, NULL , foo2, NULL ); Pthread_join(tid1, NULL ); Pthread_join(tid2, NULL ); exit (0 ); }
原理浅显,不再赘述。其中 P() 和 V() 是 csapp 对 sem_wait() 和 sem_post() 的封装函数。
这里遇到的一个问题就是不知道怎么链接 csapp对应的库。
如源码所示,代码使用 code 中的 csapp。code 的文件目录如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 (base) ➜ code tree -L 1 . ├── Makefile ├── arch ├── asm ├── conc ├── data ├── ecf ├── error ├── getasmfun.pl ├── include ├── intro ├── io ├── lib ├── link ├── mem ├── netp ├── opt ├── perf ├── src └── vm
代码引入了只引入了头文件,编译报错如下:
阅读材料:
编译的源文件中包含了头文件 csapp.h, 这个头文件中声明的函数对应的定义(也就是函数体实现)在静态库中,程序在编译的时候没有找到函数实现,因此提示 undefined reference to xxxx。
解决方案:在编译的时将静态库的路径和名字都指定出来。
-L: 指定库所在的目录(相对或者绝对路径)。-l: 指定库的名字, 需要掐头(lib)去尾(.a) 剩下的才是需要的静态库的名字(lib目录下有静态库libcsapp64.a,这是用 src 下 Makefile 使用 ar rcs 指定生成的)。
1 gcc -pthread task123.c -o task123 -I ../code/include -L ../code/lib -l csapp64
由于已经引入了头文件,起始这里是否通过 -I 指定头文件的搜索路径无关系。
-I、-L、-l 后加不加空格效果一样。-pthread:告诉编译器链接 POSIX 线程库(pthreads),以支持多线程编程。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <condition_variable> #include <iostream> #include <mutex> #include <thread> using namespace std;mutex mutex_step1_done, mutex_step2_done; condition_variable cv_step1_done, cv_step2_done; bool step1_done = false , step2_done = false ;void foo1 () cout << "step 1 is done" << endl; { lock_guard<mutex> lock (mutex_step1_done) ; step1_done = true ; } cv_step1_done.notify_one (); { unique_lock<mutex> lock (mutex_step2_done) ; cv_step2_done.wait (lock, [] { return step2_done; }); } cout << "step 3 is done" << endl; } void foo2 () { unique_lock<mutex> lock (mutex_step1_done) ; cv_step1_done.wait (lock, [] { return step1_done; }); } cout << "step 2 is done" << endl; { lock_guard<mutex> lock (mutex_step2_done) ; step2_done = true ; } cv_step2_done.notify_one (); } int main () thread t1 (foo1) ; thread t2 (foo2) ; t1.join (); t2.join (); }
上面的代码虽然简单,但也有几个点需要注意:
condition_variable.wait() 只能在 unique_ptr 上等待,而不能在 lock_guard 上等待。
1 2 3 4 5 6 7 8 task123.cc: In function ‘void foo2 () ’: task123.cc:31 :23 : error: no matching function for call to ‘std::condition_variable::wait(std::lock_guard<std::mutex>&, foo2()::<lambda()>)’ 31 | cv_step1_done.wait(lock, [] { return step1_done; }); | ~~~~~~~~~~~~~~~~~~^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ In file included from task123.cc:1 : /usr/include/c++/11 /condition_variable:100 :7 : note: candidate: ‘template <class _Predicate > void std::condition_variable::wait (std::unique_lock<std::mutex>&, _Predicate)’ 100 | wait (unique_lock<mutex>& __lock, _Predicate __p) | ^~~~
阅读材料:std::condition_variable::wait - cppreference.com
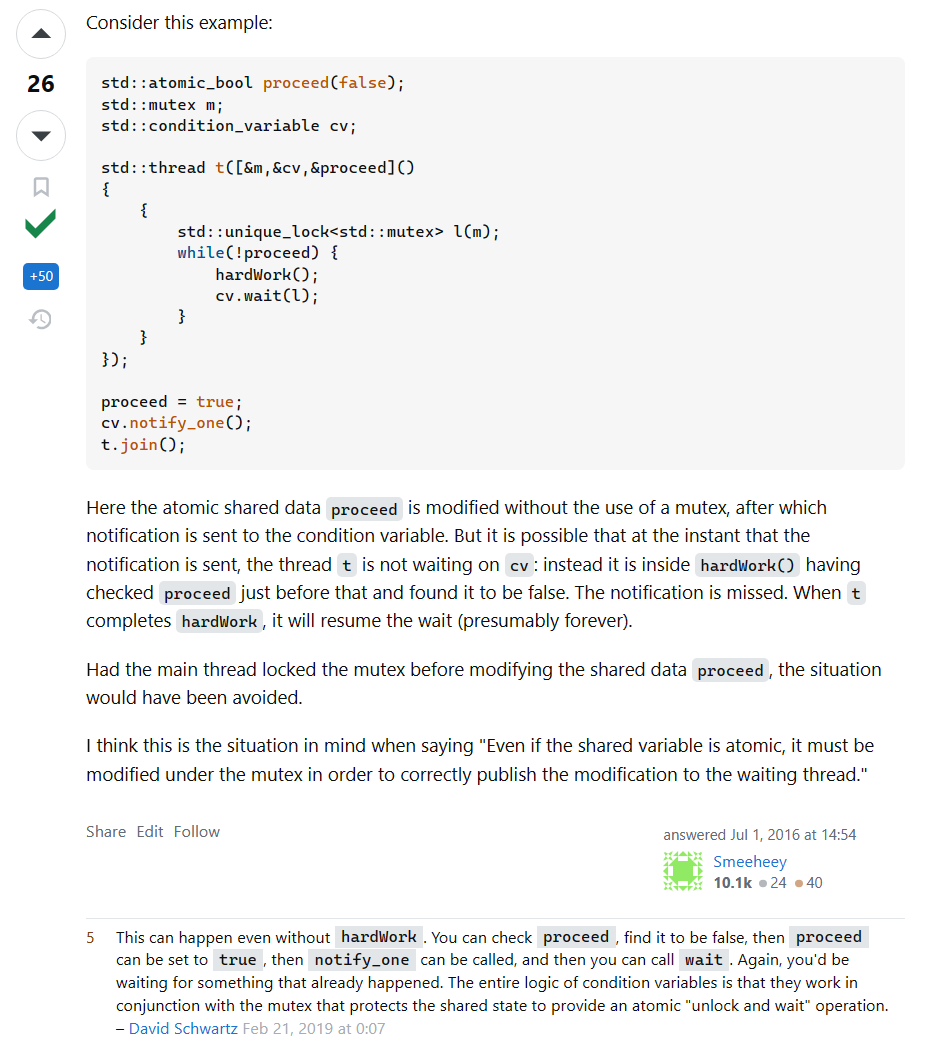
Even if the shared variable is atomic, it must be modified while owning the mutex to correctly
即使 condition_variable 在一个 atomic 的flag上等待,也是要持有 mutex 修改的,即使上面的代码中flag只会修改一次不会出问题,但是也应该养成这个好习惯。
notify_*前需要unlock,避免被唤醒的waiting线程再次被阻塞。
wait 原理建议阅读std::condition_variable::wait - cppreference.com :
Atomically calls lock.unlock() and blocks on *this.notify_all() or notify_one() is executed. It may also be unblocked spuriously.lock.lock() (possibly blocking on the lock), then returns.
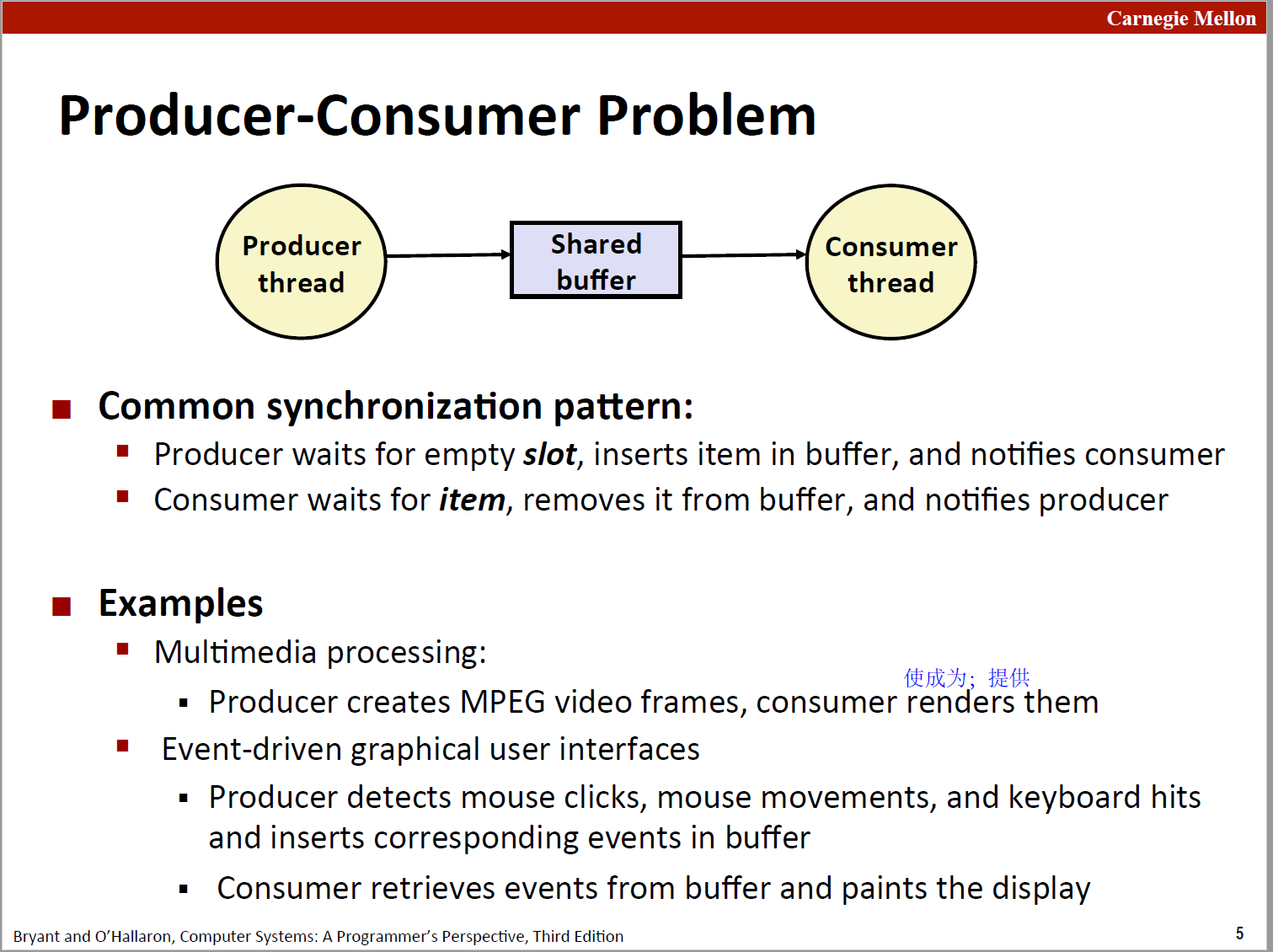
生产者 - 消费者模型
原理如下图所示:
C C++ 单生产者-单消费者 C++ 多生产者-多消费者 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void sbuf_insert (sbuf_t *sp, int item) { sem_wait(&sp->mutex); sem_wait(&sp->slots); sp->buf[(++sp->rear) % (sp->n)] = item; sem_post(&sp->items); sem_post(&sp->mutex); } void sbuf_remove (sbuf_t *sp) { int item; sem_wait(&sp->mutex); sem_wait(&sp->items); item = sp->buf[(++sp->front) % (sp->n)]; printf ("%d\n" , item); sem_post(&sp->slots); sem_post(&sp->mutex); }
代码中 mutex 目的是提供对 buf 的互斥访问,items 和 slots 是进行同步的。
这违反了pdos.csail.mit.edu/6.824/labs/raft-locking.txt (推荐阅读)中的对于预防死锁的规则:
1 2 3 4 5 6 7 8 9 10 11 Rule 4: It's usually a bad idea to hold a lock while doing anything that might wait: reading a Go channel, sending on a channel, waiting for a timer, calling time.Sleep(), or sending an RPC (and waiting for the reply). One reason is that you probably want other goroutines to make progress during the wait. Another reason is deadlock avoidance. Imagine two peers sending each other RPCs while holding locks; both RPC handlers need the receiving peer's lock; neither RPC handler can ever complete because it needs the lock held by the waiting RPC call. Code that waits should first release locks. If that's not convenient, sometimes it's useful to create a separate goroutine to do the wait.
不应该在持有互斥锁 mutex 进行耗时操作,这里只有把 mutex 的操作放到内存即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 #include <limits.h> #include <pthread.h> #include <semaphore.h> #include <stdio.h> #include <stdlib.h> #include <unistd.h> typedef struct sbuf { int *buf; int n; int rear; int front; sem_t mutex; sem_t slots; sem_t items; } sbuf_t ; void sbuf_init (sbuf_t *sp, int n) { sp->n = n; sp->buf = calloc (n, sizeof (int )); sp->rear = 0 ; sp->front = 0 ; sem_init(&sp->mutex, 0 , 1 ); sem_init(&sp->slots, 0 , n); sem_init(&sp->items, 0 , 0 ); } void sbuf_deinit (sbuf_t *sp) { free (sp->buf); }void sbuf_insert (sbuf_t *sp, int item) { sem_wait(&sp->slots); sem_wait(&sp->mutex); sp->buf[(++sp->rear) % (sp->n)] = item; sem_post(&sp->mutex); sem_post(&sp->items); } void sbuf_remove (sbuf_t *sp) { int item; sem_wait(&sp->items); sem_wait(&sp->mutex); item = sp->buf[(++sp->front) % (sp->n)]; printf ("%d\n" , item); sem_post(&sp->mutex); sem_post(&sp->slots); } void *Consumer (void *arg) { sbuf_t *sp = (sbuf_t *)arg; int i = 0 ; while (i < INT_MAX) { sbuf_insert(sp, i++); } return NULL ; } void *Producer (void *arg) { sbuf_t *sp = (sbuf_t *)arg; while (1 ) { sbuf_remove(sp); } return NULL ; } int main () { sbuf_t s; sbuf_init(&s, 3 ); pthread_t tid1, tid2; pthread_create(&tid1, NULL , Consumer, &s); pthread_create(&tid2, NULL , Producer, &s); pthread_join(tid1, NULL ); pthread_join(tid2, NULL ); sbuf_deinit(&s); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 #include <condition_variable> #include <iostream> #include <mutex> #include <queue> #include <thread> using namespace std;const int kMAX_BUFFER_SIZE = 10 ;const int kTOTAL_ITEM_NUM = 1000 ;mutex mtx; condition_variable cv_prod, cv_cons; queue<int > q; void ProducterActor (int item) unique_lock<mutex> prod_lock (mtx) ; while (q.size () == kMAX_BUFFER_SIZE) { cv_prod.wait (prod_lock); } q.push (item); prod_lock.unlock (); cv_cons.notify_all (); } int ConsumerActor () unique_lock<mutex> cons_lock (mtx) ; while (q.empty ()) { cv_cons.wait (cons_lock); } int item = q.front (); q.pop (); cons_lock.unlock (); cv_prod.notify_all (); return item; } void ProductorThread () for (int i = 0 ; i <= kTOTAL_ITEM_NUM; ++i) { ProducterActor (i); } } void ConsumerThread () while (1 ) { int item = ConsumerActor (); cout << item << endl; if (item == kTOTAL_ITEM_NUM) break ; } } int main () thread prod_t1 (ProductorThread) ; thread cons_t1 (ConsumerThread) ; prod_t1.join (); cons_t1.join (); return 0 ; }
有几个点需要注意:
notify_*前最好手动 unlock,避免被唤醒的waiting线程再次阻塞。STL容器不是线程安全的,但是这里是通过互斥锁访问的,仍然线程安全。
如果需要改成多生产者 - 多消费者,不需要改动 ProducerActor 和 ConsumerActor,只需要改动ProducerTask(名称改为Producer_thread)和ConsumerTask,程序需要维护两个计数器,分别是生产者已生产产品的数目和消费者已取走产品的数目。另外也需要保护产品库在多个生产者和多个消费者互斥地访问。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 #include <condition_variable> #include <iostream> #include <mutex> #include <queue> #include <thread> using namespace std;const int kMAX_BUFFER_SIZE = 10 ;const int kTOTAL_ITEM_NUM = 10000 ;mutex mtx; condition_variable cv_prod, cv_cons; queue<int > q; mutex producer_count_mtx, consumer_count_mtx; static std::size_t read_position = 0 ;static std::size_t write_position = 0 ;static size_t produced_item_counter = 0 ;static size_t consumed_item_counter = 0 ;chrono::seconds t (1 ) ;chrono::microseconds t1 (1000 ) ;void ProducerActor (int item) unique_lock<mutex> prod_lock (mtx) ; while (q.size () == kMAX_BUFFER_SIZE) { cv_prod.wait (prod_lock); } q.push (item); prod_lock.unlock (); cv_cons.notify_all (); } int ConsumerActor () unique_lock<mutex> cons_lock (mtx) ; while (q.empty ()) { cv_cons.wait (cons_lock); } int item = q.front (); q.pop (); cons_lock.unlock (); cv_prod.notify_all (); return item; } void ProducerThread () bool ready_to_exit = false ; while (1 ) { if (produced_item_counter >= kTOTAL_ITEM_NUM) break ; unique_lock<mutex> lck (producer_count_mtx) ; ProducerActor (produced_item_counter); ++produced_item_counter; } printf ("Producer thread %ld is exiting...\n" , this_thread::get_id ()); } void ConsumerThread () bool ready_to_exit = false ; while (1 ) { this_thread::sleep_for (t1); if (consumed_item_counter >= kTOTAL_ITEM_NUM) break ; unique_lock<mutex> lck (consumer_count_mtx) ; int item = ConsumerActor (); ++consumed_item_counter; cout << item << endl; } printf ("Consumer thread %ld is exiting...\n" , this_thread::get_id ()); } int main () vector<thread> prod_thread_vector; vector<thread> cons_thread_vector; for (int i = 0 ; i < 10 ; ++i) { prod_thread_vector.emplace_back (ProducerThread); cons_thread_vector.emplace_back (ConsumerThread); } for (auto &thr1 : prod_thread_vector) { thr1.join (); } for (auto &thr2 : cons_thread_vector) { thr2.join (); } return 0 ; }
多线程编程标准输出不要使用cout,使用 printf 输出 。
<< 本质是一次函数调用,如果有多个 << 多次函数调用肯定不是原子的,就会产生输出乱序的情况(稍微试一试就会发现这个问题),再手动加锁写起来有点麻烦,就用 printf。
TODO:本人暂时还没有系统学C++并发,可能说的会有点问题
向 vector<thread> 中添加元素时使用 emplace_back() 。
写者 - 读者模型
这一模型在多线程缓存Web代理和在线订票系统中使用。
特点:
写者必须对资源有独占的访问权限
无限多的读者可以访问资源
第一类readers-writers问题 第二类readers-writers问题 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 int read_cnt;sem_t mutex; sem_t rw; void reader (void ) { while (1 ) { P(&mutex); ++read_cnt; if (read_cnt == 1 ) { P(&rw); } V(&mutex); P(&mutex); --read_cnt; if (!read_cnt) { V(&rw); } V(&mutex); } } void writer (void ) { while (1 ) { P(&rw); V(&rw); } }
会存在“写饥饿”的问题,如果读者比较多,任意时刻读者数量都不为零,那么写者就会被饿死。
该算法是一种先到先服务的算法,对读写操作相对公平,但也会存在饥饿的情况。
和“第一类读者”代码相比,增加了 sem_t w 用于实现“相对写优先”:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 int read_cnt;sem_t mutex; sem_t rw; sem_t w; void reader (void ) { while (1 ) { P(&w); P(&mutex); ++read_cnt; if (read_cnt == 1 ) { P(&rw); } V(&mutex); V(&w); P(&mutex); --read_cnt; if (!read_cnt) { V(&rw); } V(&mutex); } } void writer (void ) { while (1 ) { P(&w); P(&rw); V(&rw); V(&w); } }
分析一下 读者1 -> 写者1 -> 读者2 这种情况。
第一个读者1在进行到读文件操作的时候,有一个写者1操作,由于第一个读者1执行了V(w),所以写者1不会阻塞在P(w),但由于第一个读者1执行了P(rw)但没有执行V(rw),写者1将会被阻塞在P(rw)上。
这时再有一个读者2,由于前面的写者1进程执行了P(w)但没有执行V(w),所以读者2将会被阻塞在P(w)上,这样写者1和读者2都将阻塞,只有当读者1结束时执行V(rw),此时写者1才能够继续执行直到执行V(w),读者2也将能够执行下去。
echo-server 实现
普通版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include "../code/include/csapp.h" void echo (int conn_fd) { rio_t rio; Rio_readinitb(&rio, conn_fd); int n; char buf[MAXLINE]; while ((n = Rio_readlineb(&rio, buf, MAXLINE)) > 0 ) { printf ("receive from client %s\n" , buf); Rio_writen(rio.rio_fd, buf, n); } } void *thread (void *argvp) { int conn_fd = *((int *)argvp); Free(argvp); echo(conn_fd); Close(conn_fd); return NULL ; } int main (int argc, char **argv) { if (argc != 2 ) { unix_error("usage: ./server <port>" ); } char *port = argv[1 ]; int listen_fd = Open_listenfd(port); int *conn_fd; struct sockaddr_storage client_addr ; socklen_t addr_len; pthread_t tid; while (1 ) { addr_len = sizeof (struct sockaddr_storage); conn_fd = Malloc(sizeof (int )); *conn_fd = Accept(listen_fd, (SA *)&client_addr, &addr_len); Pthread_create(&tid, NULL , thread, conn_fd); } }
这里比较重要的是:
1 2 3 conn_fd = Malloc (sizeof (int )); *conn_fd = Accept (listen_fd, (SA *)&client_addr, &addr_len); Pthread_create (&tid, NULL , thread, conn_fd);
郭郭:“并发的核心问题是多线程/多进程对共享内存区域的控制问题。”
这里向子线程传递的是 conn_fd(指针),即堆上的一个地址, 子线程解引用的得到的就是conn套接字的文件描述符。pthread_create 传参时需要传void*, 在子线程中对void*指针进行类型强制转换再解引用即可。
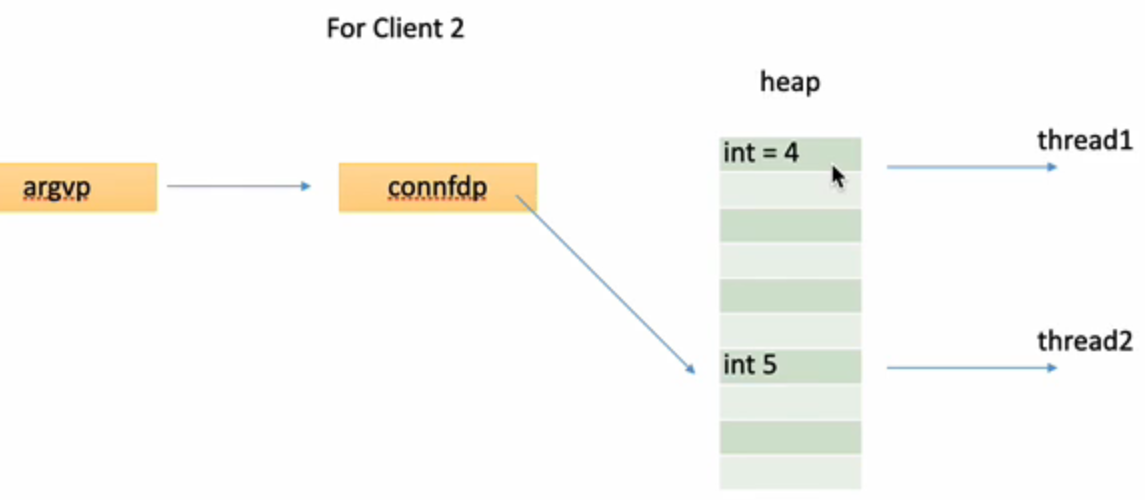
注意这里不能传&conn_fd:
不能假设子线程解引用早于父线程 *conn_fd = Accept(listen_fd, (SA *)&client_addr, &addr_len) 发生,如果conn_fd改变了,子线程中两次解引用得到的是新的conn套接字的文件描述符,如下图所示:
这个问题和pdos.csail.mit.edu/6.824/labs/raft-locking.txt 中的第5点是一致的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 Rule 5: Be careful about assumptions across a drop and re-acquire of a lock. One place this can arise is when avoiding waiting with locks held. For example, this code to send vote RPCs is incorrect: rf.mu.Lock() rf.currentTerm += 1 rf.state = Candidate for <each peer> { go func() { rf.mu.Lock() args.Term = rf.currentTerm rf.mu.Unlock() Call("Raft.RequestVote", &args, ...) // handle the reply... } () } rf.mu.Unlock() The code sends each RPC in a separate goroutine. It's incorrect because args.Term may not be the same as the rf.currentTerm at which the surrounding code decided to become a Candidate. Lots of time may pass between when the surrounding code creates the goroutine and when the goroutine reads rf.currentTerm; for example, multiple terms may come and go, and the peer may no longer be a candidate. One way to fix this is for the created goroutine to use a copy of rf.currentTerm made while the outer code holds the lock. Similarly, reply-handling code after the Call() must re-check all relevant assumptions after re-acquiring the lock; for example, it should check that rf.currentTerm hasn't changed since the decision to become a candidate.
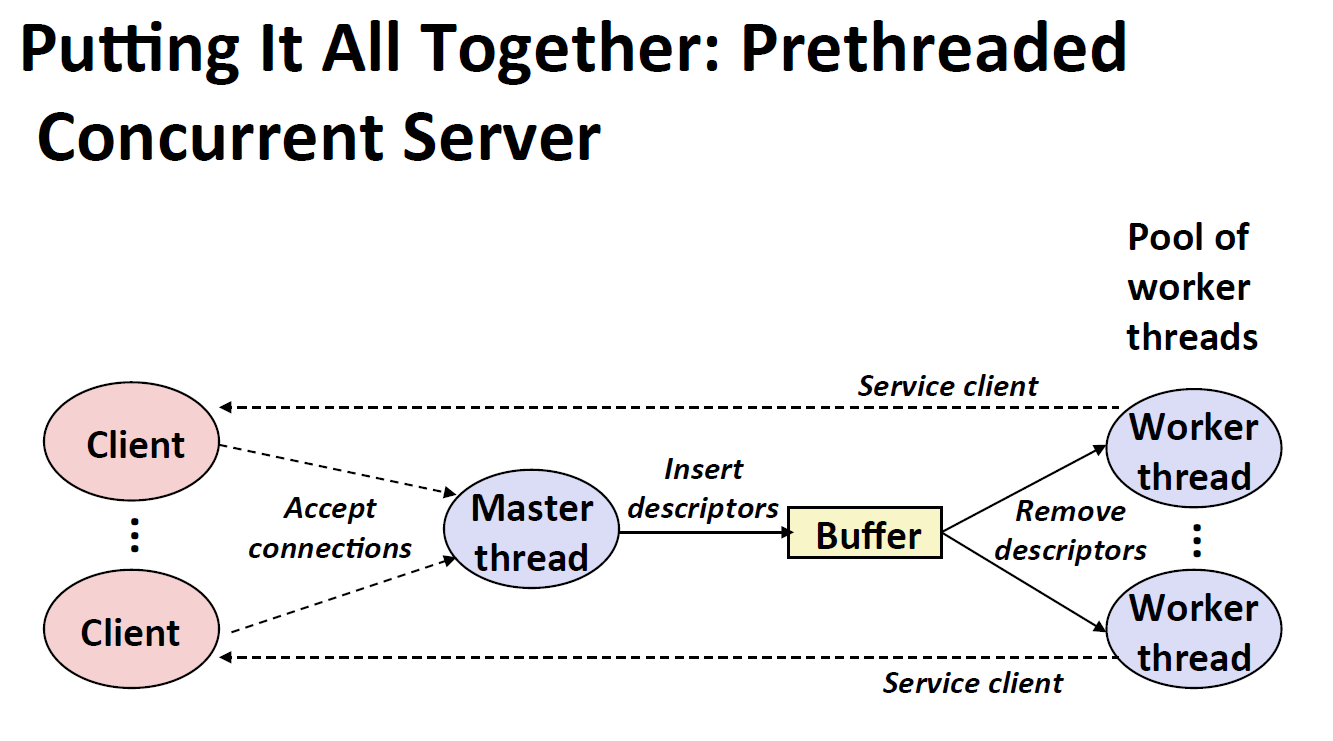
线程池版本
模型
实现
echoservert_pre.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include "csapp.h" #include "sbuf.h" #define NTHREADS 4 #define SBUFSIZE 16 void echo_cnt (int connfd) ;void *thread (void *vargp) ;sbuf_t sbuf; int main (int argc, char **argv) { int i, listenfd, connfd; socklen_t clientlen; struct sockaddr_storage clientaddr ; pthread_t tid; if (argc != 2 ) { fprintf (stderr , "usage: %s <port>\n" , argv[0 ]); exit (0 ); } listenfd = Open_listenfd(argv[1 ]); sbuf_init(&sbuf, SBUFSIZE); for (i = 0 ; i < NTHREADS; i++) Pthread_create(&tid, NULL , thread, NULL ); while (1 ) { clientlen = sizeof (struct sockaddr_storage); connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen); sbuf_insert(&sbuf, connfd); } } void *thread (void *vargp) { Pthread_detach(pthread_self()); while (1 ) { int connfd = sbuf_remove(&sbuf); echo_cnt(connfd); Close(connfd); } }
echo_cnt.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #include "csapp.h" static int byte_cnt; static sem_t mutex; static void init_echo_cnt (void ) { Sem_init(&mutex, 0 , 1 ); byte_cnt = 0 ; } void echo_cnt (int connfd) { int n; char buf[MAXLINE]; rio_t rio; static pthread_once_t once = PTHREAD_ONCE_INIT; Pthread_once(&once, init_echo_cnt); Rio_readinitb(&rio, connfd); while ((n = Rio_readlineb(&rio, buf, MAXLINE)) != 0 ) { P(&mutex); byte_cnt += n; printf ("server received %d (%d total) bytes on fd %d\n" , n, byte_cnt, connfd); V(&mutex); Rio_writen(connfd, buf, n); } }
静态局部变量:和全局变量类似,只不过范围限制在此函数中,但执行此函数的每个线程都可以访问它。如果一个线程更新该值,则每个线程都会看到相同修改过的值。
对于 Rio_writen(connfd, buf, n),不需要持有锁,同时也尽量不要在持有锁时进行耗时操作,所以在这之前释放锁。