掌握Hadoop DFS常用指令
1. Hadoop 使用方法
在服务器上,我们通过Linux 指令对本地文件系统进行操作,如使用 ls 查看文件/目录信息、使用 cp进行文件复制、使用 cat 查看文件内容。在分布式文件系统中,也有一套相似的指令,接下来我们需要掌握一些基本的指令。(本题 1 分)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 xxxxxxxxxx@thumm01:~$ hadoop fs -ls / Found 2 items drwxr-xr-x - root supergroup 0 2023-10-06 20:48 /dsjxtjc drwxrwxrwx - jtliu supergroup 0 2020-12-21 23:25 /tmp xxxxxxxxxx@thumm01:~$ hadoop fs -ls /dsjxtjc/xxxxxxxxxx xxxxxxxxxx@thumm01:~$ touch test.txt xxxxxxxxxx@thumm01:~$ echo "Hello Hadoop" > test.txt xxxxxxxxxx@thumm01:~$ cat test.txt Hello Hadoop xxxxxxxxxx@thumm01:~$ hadoop fs -copyFromLocal ./test.txt /dsjxtjc/xxxxxxxxxx/ 2023-10-31 20:31:31,606 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false , remoteHostTrusted = false xxxxxxxxxx@thumm01:~$ hadoop fs -cat /dsjxtjc/xxxxxxxxxx/test.txt 2023-10-31 20:32:01,519 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false , remoteHostTrusted = false Hello Hadoop
2. 通过Web查看Hadoop运行情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 Windows PowerShell 版权所有(C) Microsoft Corporation。保留所有权利。 安装最新的 PowerShell,了解新功能和改进!https://aka.ms/PSWindows PS C:\Users\jkup> ssh xxxxxxxxxx@10.103 .9.11 -L 9870 :192.169 .0.101 :9870 Welcome to Ubuntu 16.04 .7 LTS (GNU/Linux 4.4 .0 -210-generic x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage UA Infra: Extended Security Maintenance (ESM) is not enabled. 0 updates can be applied immediately.307 additional security updates can be applied with UA Infra: ESMLearn more about enabling UA Infra: ESM service for Ubuntu 16.04 at https://ubuntu.com/16 -04 Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. New release '18.04.6 LTS' available. Run 'do-release-upgrade' to upgrade to it. Last login: Tue Oct 31 19 :57 :30 2023 from 10.81 .32.116 xxxxxxxxxx@thumm01:~$
分布式文件系统
copyFromLocal
copyFromLocal 的功能是将本地文件传到DFS之中。具体来说, client 会把文件信息通过new_fat_item 指令给NameNode,NameNode根据文件大小分配空间,并将相应空间信息以FAT表的形式返回给 client.py (详见 name_node.py 中的 new_fat_item 函数);接着,Client 根据FAT表和目标节点逐个建立连接发送数据块。
name_node.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def new_fat_item (self, dfs_path, file_size ): nb_blks = int (math.ceil(file_size / DFS_BLK_SIZE)) print (file_size, nb_blks) data_pd = pd.DataFrame(columns=['blk_no' , 'host_name' , 'blk_size' ]) for i in range (nb_blks): blk_no = i host_name = np.random.choice(HOST_LIST, size=DFS_REPLICATION, replace=False ) blk_size = min (DFS_BLK_SIZE, file_size - i * DFS_BLK_SIZE) data_pd.loc[i] = [blk_no, host_name, blk_size] local_path = os.path.join(NAME_NODE_DIR, dfs_path) os.system("mkdir -p {}" .format (os.path.dirname(local_path))) data_pd.to_csv(local_path, index=False ) return data_pd.to_csv(index=False )
data_node.py
1 2 3 4 5 6 7 8 9 10 11 12 def store (self, sock_fd, dfs_path ): chunk_data = sock_fd.recv(BUF_SIZE) local_path = os.path.join(DATA_NODE_DIR, dfs_path) os.system("mkdir -p {}" .format (os.path.dirname(local_path))) with open (local_path, "wb" ) as f: f.write(chunk_data) return "Store chunk {} successfully~" .format (local_path)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 def copyFromLocal (self, local_path, dfs_path ): file_size = os.path.getsize(local_path) print ("File size: {}" .format (file_size)) request = "new_fat_item {} {}" .format (dfs_path, file_size) print ("Request: {}" .format (request)) self.name_node_sock.send(bytes (request, encoding='utf-8' )) fat_pd = self.name_node_sock.recv(BUF_SIZE) fat_pd = str (fat_pd, encoding='utf-8' ) print ("Fat: \n{}" .format (fat_pd)) fat = pd.read_csv(StringIO(fat_pd)) with open (local_path) as fp: for idx, row in fat.iterrows(): data = fp.read(int (row['blk_size' ])) datanode_hosts = re.findall(r"'(.+?)'" , row['host_name' ]) for host in datanode_hosts: data_node_sock = socket.socket() data_node_sock.connect((host, DATA_NODE_PORT)) blk_path = dfs_path + ".blk{}" .format (row['blk_no' ]) request = "store {}" .format (blk_path) data_node_sock.send(bytes (request, encoding='utf-8' )) time.sleep(0.2 ) data_node_sock.send(bytes (data, encoding='utf-8' )) data_node_sock.close()
扩展:
1.TCP粘包问题
发送方两次发送间隔一段时间(低性能),或发送方关闭Nagle算法
接受方简单的处理思路如下,随着需求演化,逐渐形成了应用层协议:
在数据流中设置分段标志,比如C语言字符串使用’\n’作为字符串结束标志,但这又涉及到一个转义和不安全的问题。
设置收发格式,比如规定前多少字节表示packet的大小,这也是后面实验中使用的方法。
只有TCP存在粘包问题,因为TCP是面向流的,而UDP是面向消息的,有消息边界。
2.StringIO
io 模块中的 io.StringIO 能生成内存中的类文件对象(in-memory file-like object),此对象可用作需要标准文件对象的大多数函数的输入或输出。
3.正则表达式
datanode_hosts = re.findall(r"'(.+?)'", row['host_name'])
row['host_name']是一个string,值为"['thumm01' 'thumm03' 'thumm05']"
pattern中的r表示字符串,还可以用b表示字节。
. 表示匹配除“\n\n(.|\n)”的模式。
+ 表示匹配前面的子表达式一次或多次。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。
? 表示非贪婪模式。当该字符紧跟在任何一个其他限制符(*,+,?,{n },{n ,},{n ,m })后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串“oooo”,“o+?”将匹配单个“o”,而“o+”将匹配所有“o”
re.findall(r"'(.+?)'", row['host_name'] 结果为一个list,为['thumm01', 'thumm03', 'thumm05']
每次一个个去启动数据节点上的太麻烦了,还是写个通过ssh统一控制数据节点的脚本。
第10行的kill命令作用不大,数据节点上的后台进程删不干净(权限不够),这里采取的方法是修改端口重新运行,对不起啦(
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #!/bin/bash HOST_LIST=('thumm01' 'thumm03' 'thumm04' 'thumm05' "thumm06" ) for server in ${HOST_LIST[@]} do ssh $server " rm -rf ~/lab2/MyDFS/dfs/data/*; scp -r thumm01:~/lab2/MyDFS ~/lab2/ cd ~/lab2/MyDFS; # kill -9 \$(ps -ef | grep MyDFS | awk '{print \$2}'); python3 data_node.py; " &done wait
如果第11行用python通过bash pipeline.sh 运行时可能得报错: SyntaxError: Non-ASCII character '\xe6' in file data_node.py on line 7, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details,还会遇到 str() takes at most 1 argument (2 given) 的报错。
1 2 3 4 xxxxxxxxxx@thumm05:~$ which python /usr/bin/python xxxxxxxxxx@thumm05:~$ ls -al /usr/bin/python lrwxrwxrwx 1 root root 9 Nov 23 2017 /usr/bin/python -> python2.7
运行
这里使用的已经是添加数据切边冗余备份的代码,各数据节点上的数据切片详见data replication 一节。
1 2 3 4 5 6 7 8 xxxxxxxxxx@thumm01:~/lab2/MyDFS$ python client.py -copyFromLocal ./test/test_copyFromLocal.txt test_copyFromLocal.txt File size: 8411 Request: new_fat_item test_copyFromLocal.txt 8411 Fat: blk_no,host_name,blk_size 0,['thumm05' 'thumm01' 'thumm06' ],4096 1,['thumm03' 'thumm01' 'thumm06' ],4096 2,['thumm05' 'thumm01' 'thumm06' ],219
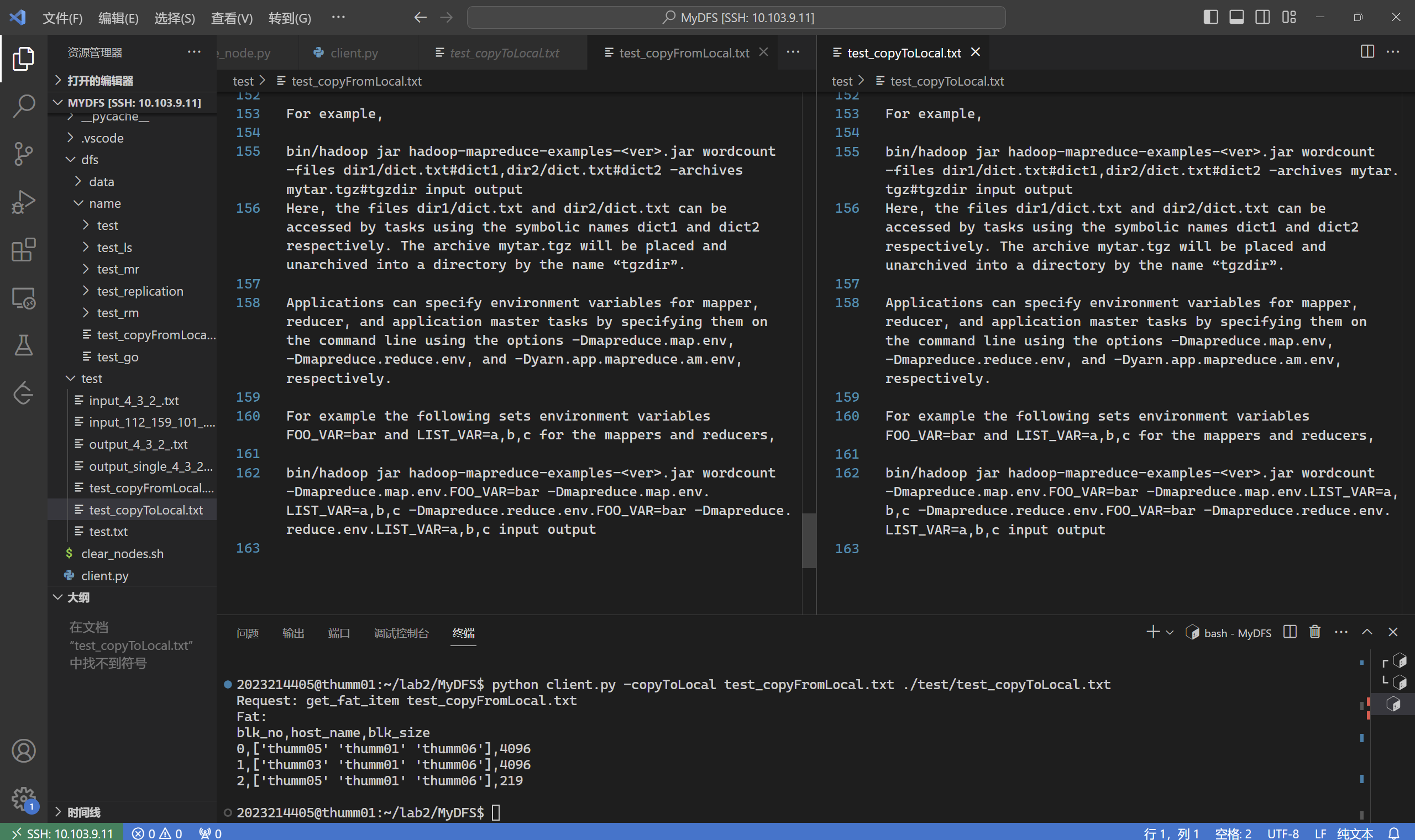
copyToLocal
copyToLocal 是 copyFromLocal 的反向操作
name_node.py
1 2 3 4 5 def get_fat_item (self, dfs_path ): local_path = os.path.join(NAME_NODE_DIR, dfs_path) response = pd.read_csv(local_path) return response.to_csv(index=False )
data_node.py
1 2 3 4 5 6 7 8 9 10 11 12 def store (self, sock_fd, dfs_path ): chunk_data = sock_fd.recv(BUF_SIZE) local_path = os.path.join(DATA_NODE_DIR, dfs_path) os.system("mkdir -p {}" .format (os.path.dirname(local_path))) with open (local_path, "wb" ) as f: f.write(chunk_data) return "Store chunk {} successfully~" .format (local_path)
从NameNode获取一张FAT表
打印FAT表
根据FAT表逐个从目标DataNode请求数据块,写入到本地文件中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def copyToLocal (self, dfs_path, local_path ): request = "get_fat_item {}" .format (dfs_path) print ("Request: {}" .format (request)) self.name_node_sock.send(bytes (request, encoding='utf-8' )) fat_pd = self.name_node_sock.recv(BUF_SIZE) fat_pd = str (fat_pd, encoding='utf-8' ) print ("Fat: \n{}" .format (fat_pd)) fat = pd.read_csv(StringIO(fat_pd)) with open (local_path, "w" ) as fp: for idx, row in fat.iterrows(): datanode_hosts = re.findall(r"'(.+?)'" , row['host_name' ]) data_node_sock = socket.socket() data_node_sock.connect((datanode_hosts[0 ], DATA_NODE_PORT)) blk_path = dfs_path + '.blk{}' .format (row['blk_no' ]) request = "load {}" .format (blk_path) data_node_sock.send(bytes (request, encoding='utf-8' )) time.sleep(0.2 ) recv_data = data_node_sock.recv(BUF_SIZE) data_node_sock.close() fp.write(str (recv_data, encoding='utf-8' ))
运行
1 2 3 4 5 6 7 xxxxxxxxxx@thumm01:~/lab2/MyDFS$ python client.py -copyToLocal test_copyFromLocal.txt ./test/test_copyToLocal.txt Request: get_fat_item test_copyFromLocal.txt Fat: blk_no,host_name,blk_size 0,['thumm05' 'thumm01' 'thumm06' ],4096 1,['thumm03' 'thumm01' 'thumm06' ],4096 2,['thumm05' 'thumm01' 'thumm06' ],219
ls
name_node.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def ls (self, dfs_path ): local_path = os.path.join(NAME_NODE_DIR, dfs_path) if not os.path.exists(local_path): return "No such file or directory: {}" .format (dfs_path) if os.path.isdir(local_path): dirs = os.listdir(local_path) response = " " .join(dirs) else : with open (local_path) as f: response = f.read() return response
Client 会向NameNode 发送请求,查看 dfs_path 下的文件或文件夹信息
向NameNode发送请求,查看dfs_path下文件或者文件夹信息
1 2 3 4 5 6 7 def ls (self, dfs_path ): request = "ls {} " .format (dfs_path) self.name_node_sock.send(bytes (request, encoding='utf-8' )) fat_pd = self.name_node_sock.recv(BUF_SIZE) fat_pd = str (fat_pd, encoding='utf-8' ) print ("file: \n{}" .format (fat_pd))
运行
向dfs中test_ls文件夹中上传2文件后,使用ls测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 xxxxxxxxxx@thumm01:~/lab2/MyDFS$ python client.py -format format Format namenode successfully~ Format datanode successfully~ Format datanode successfully~ Format datanode successfully~ Format datanode successfully~ Format datanode successfully~ xxxxxxxxxx@thumm01:~/lab2/MyDFS$ python client.py -copyFromLocal ./test/test_copyToLocal.txt test_ls/test_ls0.txt File size: 8411 Request: new_fat_item test_ls/test_ls0.txt 8411 Fat: blk_no,host_name,blk_size 0,['thumm01' 'thumm03' 'thumm05' ],4096 1,['thumm03' 'thumm01' 'thumm05' ],4096 2,['thumm04' 'thumm01' 'thumm06' ],219 xxxxxxxxxx@thumm01:~/lab2/MyDFS$ python client.py -copyFromLocal ./test/test_copyToLocal.txt test_ls/test_ls0.txt File size: 8411 Request: new_fat_item test_ls/test_ls0.txt 8411 Fat: blk_no,host_name,blk_size 0,['thumm04' 'thumm01' 'thumm06' ],4096 1,['thumm06' 'thumm05' 'thumm04' ],4096 2,['thumm05' 'thumm06' 'thumm01' ],219 xxxxxxxxxx@thumm01:~/lab2/MyDFS$ python client.py -ls test_ls file: test_ls0.txt xxxxxxxxxx@thumm01:~/lab2/MyDFS$ python client.py -ls NoExisted.txt file: No such file or directory: NoExisted.txt xxxxxxxxxx@thumm01:~/lab2/MyDFS$ python client.py -ls dir /test_ls0.txt file: No such file or directory: dir /test_ls0.txt
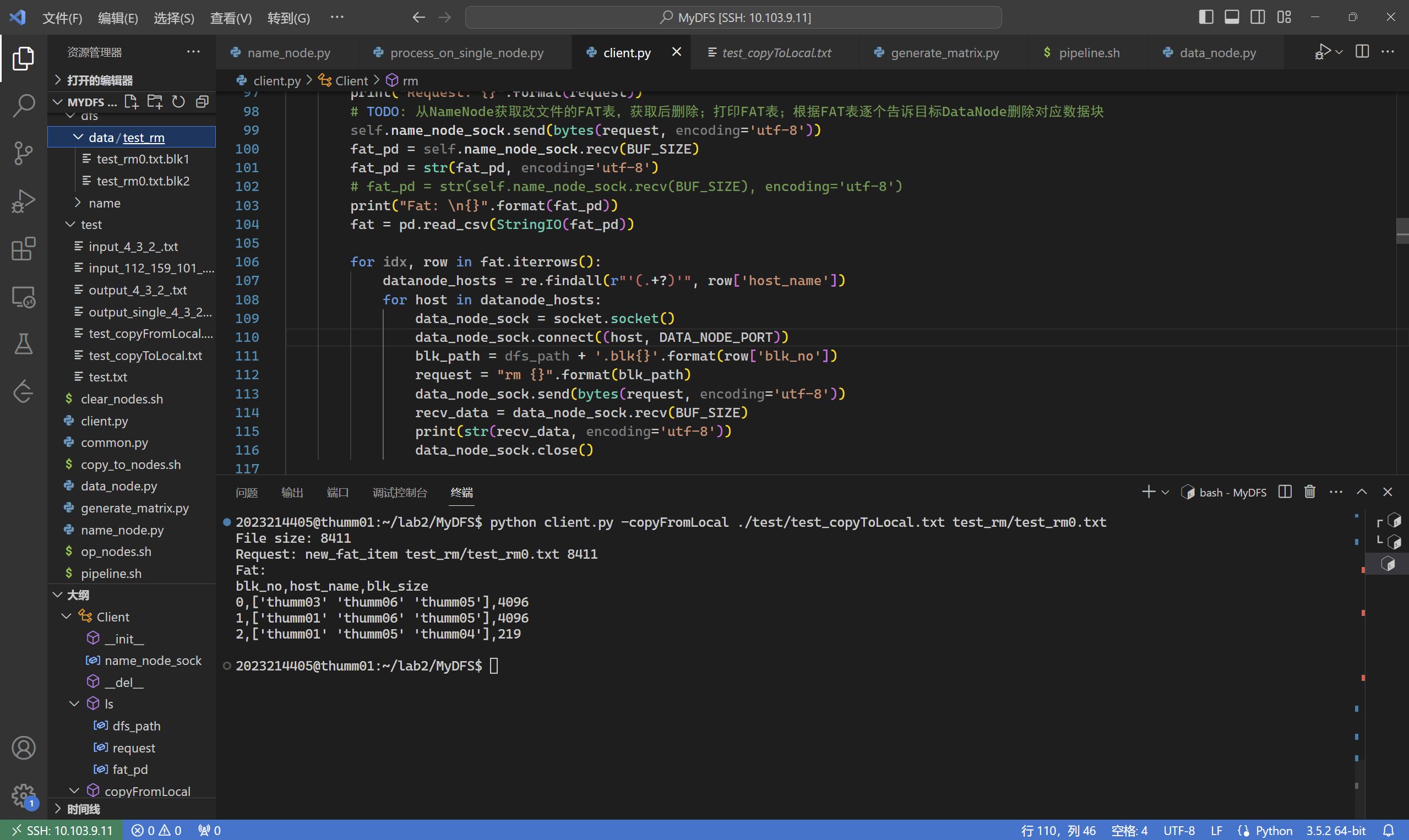
rm
rm: 删除相应路径的文件。
name_node.py
1 2 3 4 5 def rm_fat_item (self, dfs_path ): local_path = NAME_NODE_DIR + dfs_path response = pd.read_csv(local_path) os.remove(local_path) return response.to_csv(index=False )
data_node.py
1 2 3 4 def rm (self, dfs_path ): local_path = os.path.join(DATA_NODE_DIR, dfs_path) rm_command = "rm -rf " + local_path os.system(rm_command)
从NameNode获取改文件的FAT表,获取后NameNode删除对应记录
打印FAT表
根据FAT表逐个告诉目标DataNode删除对应数据块
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def rm (self, dfs_path ): request = "rm_fat_item {}" .format (dfs_path) print ("Request: {}" .format (request)) self.name_node_sock.send(bytes (request, encoding='utf-8' )) fat_pd = self.name_node_sock.recv(BUF_SIZE) fat_pd = str (fat_pd, encoding='utf-8' ) print ("Fat: \n{}" .format (fat_pd)) fat = pd.read_csv(StringIO(fat_pd)) for idx, row in fat.iterrows(): data_node_sock = socket.socket() data_node_sock.connect((row['host_name' ], DATA_NODE_PORT)) blk_path = dfs_path + '.blk{}' .format (row['blk_no' ]) request = "rm {}" .format (blk_path) data_node_sock.send(bytes (request, encoding='utf-8' )) recv_data = data_node_sock.recv(BUF_SIZE) print (str (recv_data, encoding='utf-8' )) data_node_sock.close()
运行
执行结果如下,在./dfs/name和./dfs/data中的文件被删除
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 xxxxxxxxxx@thumm01:~/lab2/MyDFS$ python client.py -copyFromLocal ./test/test_copyToLocal.txt test_rm/test_rm0.txt File size: 8411 Request: new_fat_item test_rm/test_rm0.txt 8411 Fat: blk_no,host_name,blk_size 0,['thumm03' 'thumm06' 'thumm05' ],4096 1,['thumm01' 'thumm06' 'thumm05' ],4096 2,['thumm01' 'thumm05' 'thumm04' ],219 xxxxxxxxxx@thumm01:~/lab2/MyDFS$ python client.py -rm test_rm/test_rm0.txt Request: rm_fat_item test_rm/test_rm0.txt Fat: blk_no,host_name,blk_size 0,['thumm03' 'thumm06' 'thumm05' ],4096 1,['thumm01' 'thumm06' 'thumm05' ],4096 2,['thumm01' 'thumm05' 'thumm04' ],219 Remove chunk ./dfs/data/test_rm/test_rm0.txt.blk0 successfully~ Remove chunk ./dfs/data/test_rm/test_rm0.txt.blk0 successfully~ Remove chunk ./dfs/data/test_rm/test_rm0.txt.blk0 successfully~ Remove chunk ./dfs/data/test_rm/test_rm0.txt.blk1 successfully~ Remove chunk ./dfs/data/test_rm/test_rm0.txt.blk1 successfully~ Remove chunk ./dfs/data/test_rm/test_rm0.txt.blk1 successfully~ Remove chunk ./dfs/data/test_rm/test_rm0.txt.blk2 successfully~ Remove chunk ./dfs/data/test_rm/test_rm0.txt.blk2 successfully~ Remove chunk ./dfs/data/test_rm/test_rm0.txt.blk2 successfully~ xxxxxxxxxx@thumm01:~/lab2/MyDFS$ ls dfs/data/test_rm/ xxxxxxxxxx@thumm01:~/lab2/MyDFS$
data replication
目前common.py中DFS_REPLICATION为1,意为每个数据块只存储在一台主机上。实际上从系统稳定性考虑,每个数据块会被存放在多台主机。请修改DFS_REPLICATION和HOST_LIST,以及namenode.py 、datanode.py 、client.py中对应的部分,实现多副本块存储。推荐dfs_replicatio=3 ,在5台机器上测试。
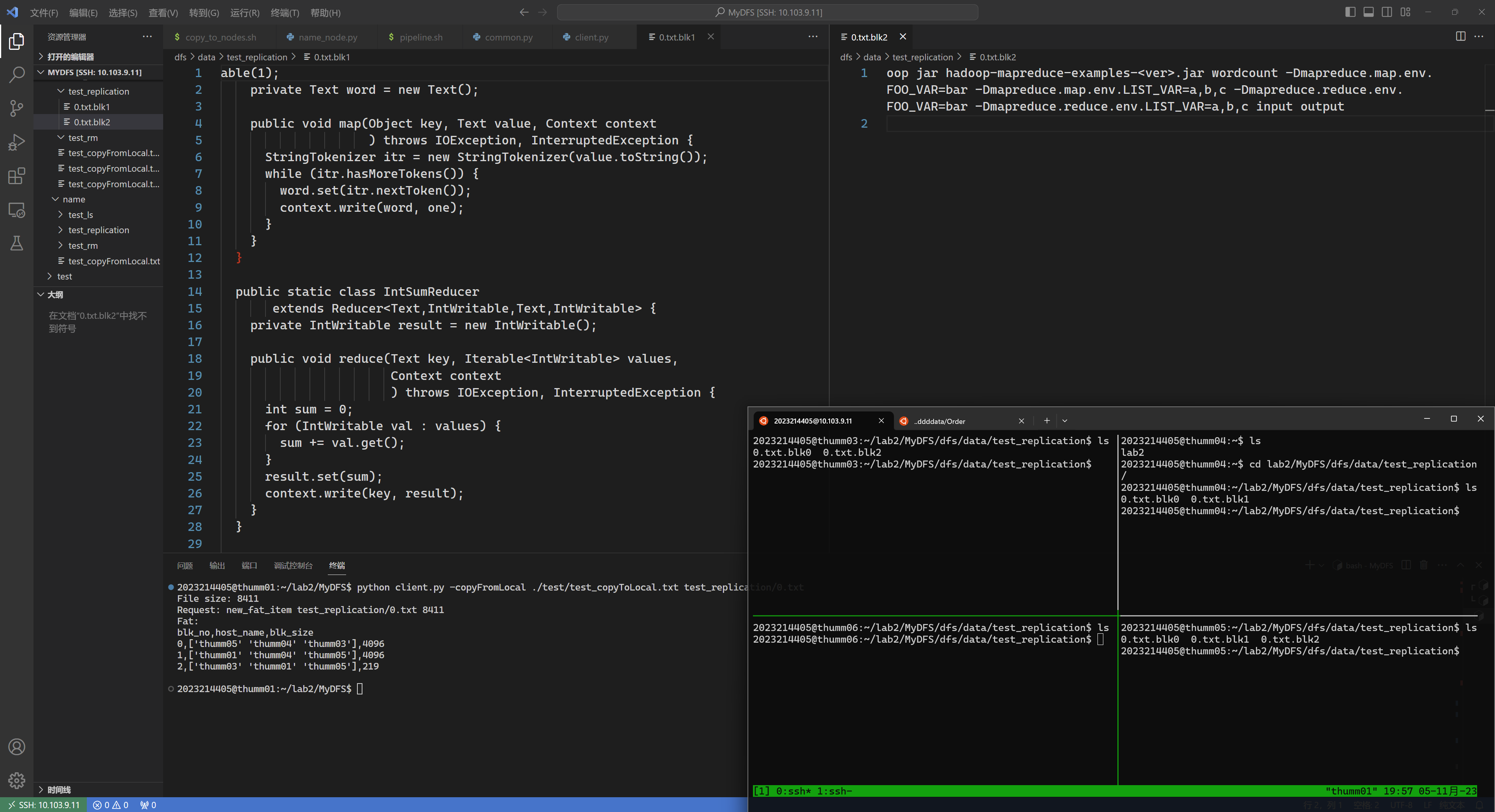
以上代码和运行结果已经使用了 data replication:
1 python client.py -copyFromLocal ./test/test_copyToLocal.txt test_replication/0.txt
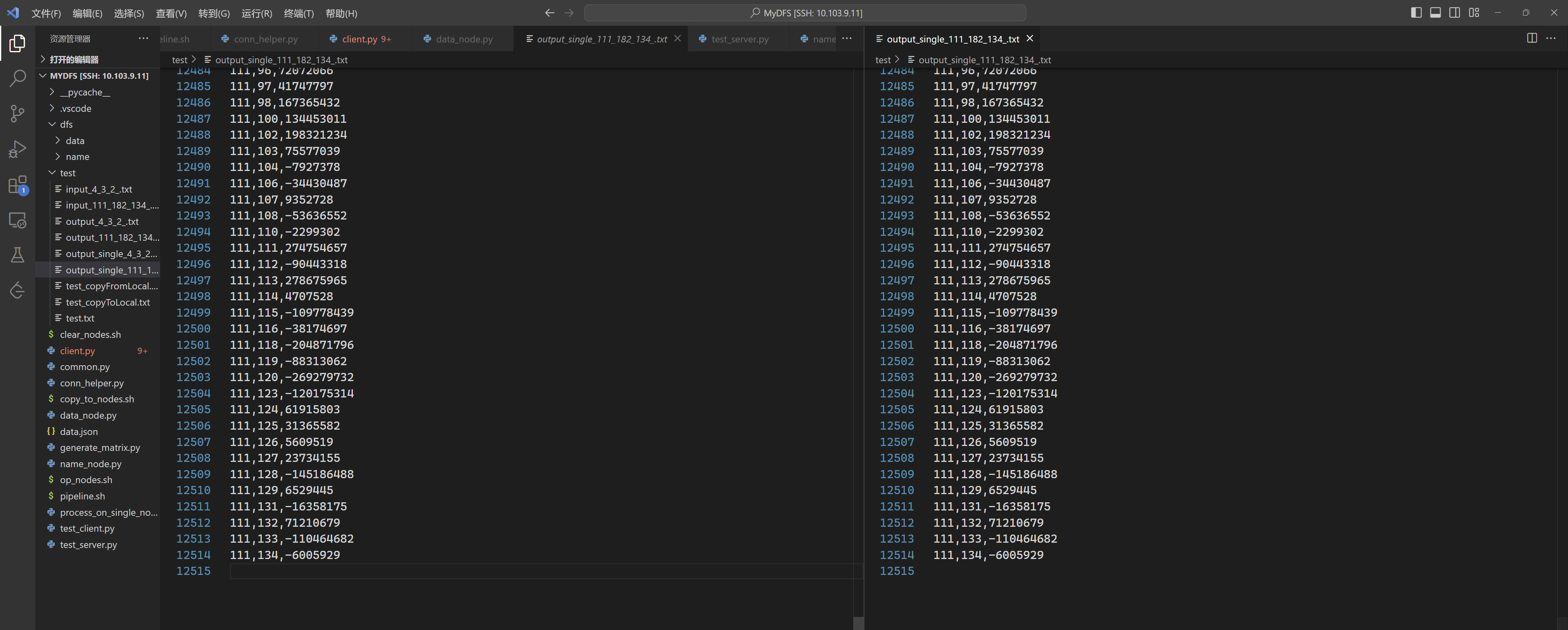
如下图所示,通过vscode文本框可以看到thum01中有1和2块,通过tmux中左上分窗可以看到thumm03上有0和2号块……且其他节点上确实有对应块,且块中内容均正确。
MapReduce 实现稀疏矩阵乘法
数据”断裂“问题
在前面的程序中,client在上传文件时会向name_node发文件总大小,name_node再按照固定字节数的方式进行分块,这样带来了一个巨大的问题:
由于name_node无法访问原文件,因此更改方法只能是client进行预分块,client保证每块大小尽可能接近DFS_BLK_SIZE且每个分块中数据都是完整的,并把各个分块的大小上传给name_node。
但如果某个数据特别大,超过DFS_BLK_SIZE,那么上面的处理会导致没有该数据不能放进DFS(死循环)。
client 计算分块大小
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def preCalculateFileSize (self, local_file ): blk_size_list = [] cur_blk_size = 0 with open (local_file, "rb" ) as f: for line in f.readlines(): if (cur_blk_size + len (line)) > DFS_BLK_SIZE: blk_size_list.append(cur_blk_size) cur_blk_size = len (line) else : cur_blk_size += len (line) if cur_blk_size: blk_size_list.append(cur_blk_size) return blk_size_list
问题记录:按字节读取和按字符读取
问题:os.path.getsize 和 按行读取字符这总数不相等。\n的,在len()时也会被计入长度,本人测试是占一个字节。
1 2 3 4 5 6 7 8 9 10 >>> os.path.getsize("test.txt" )8411 >>> s = 0 >>> f = open ("test.txt" , "r" )>>> for line in f.readlines():... s += len (line)... ... >>> s8399
经过测试换行符\n和缩进、空格都不会引发长度计数的问题,那究竟是什么导致了长度不相等的问题呢?
原因在于非ASCII字符 ,比如™在len()时长度为2,而在字节模式中占4个字符 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 >>> f1 = open ("test.txt" )>>> f2 = open ("test.txt" , "rb" )>>> ls1 = f1.readlines()>>> ls2 = f2.readlines()>>> for i in range (len (ls1)):... if (len (ls1[i]) != len (ls2[i])):... print (f"len(ls1[i]) = {len (ls1[i])} len(ls2[i]) = {len (ls2[i])} " )... print (ls1[i], end='' )... print (ls2[i])... ... ... len (ls1[i]) = 107 len (ls2[i]) = 109 Although the Hadoop framework is implemented in Java™, MapReduce applications need not be written in Java. b'Although the Hadoop framework is implemented in Java\xe2\x84\xa2, MapReduce applications need not be written in Java.\n' len (ls1[i]) = 96 len (ls2[i]) = 98 Hadoop Pipes is a SWIG-compatible C++ API to implement MapReduce applications (non JNI™ based). b'Hadoop Pipes is a SWIG-compatible C++ API to implement MapReduce applications (non JNI\xe2\x84\xa2 based).\n' len (ls1[i]) = 94 len (ls2[i]) = 98 Here, myarchive.zip will be placed and unzipped into a directory by the name “myarchive.zip ”. b'Here, myarchive.zip will be placed and unzipped into a directory by the name \xe2\x80\x9cmyarchive.zip\xe2\x80\x9d.\n' len (ls1[i]) = 219 len (ls2[i]) = 223 Here, the files dir1/dict .txt and dir2/dict .txt can be accessed by tasks using the symbolic names dict1 and dict2 respectively. The archive mytar .tgz will be placed and unarchived into a directory by the name “tgzdir”. b'Here, the files dir1/dict.txt and dir2/dict.txt can be accessed by tasks using the symbolic names dict1 and dict2 respectively. The archive myt ar.tgz will be placed and unarchived into a directory by the name \xe2\x80\x9ctgzdir\xe2\x80\x9d.\n
总结:以后遇到这种操作都应该采用字节模式读取。
conn_helper.py:packet设计
如上一节,传输对象不限于字符串,还涉及到了列表等对象,此外由于发送方和接收方的缓冲区有限,有必要设计单独的通信工具函数。
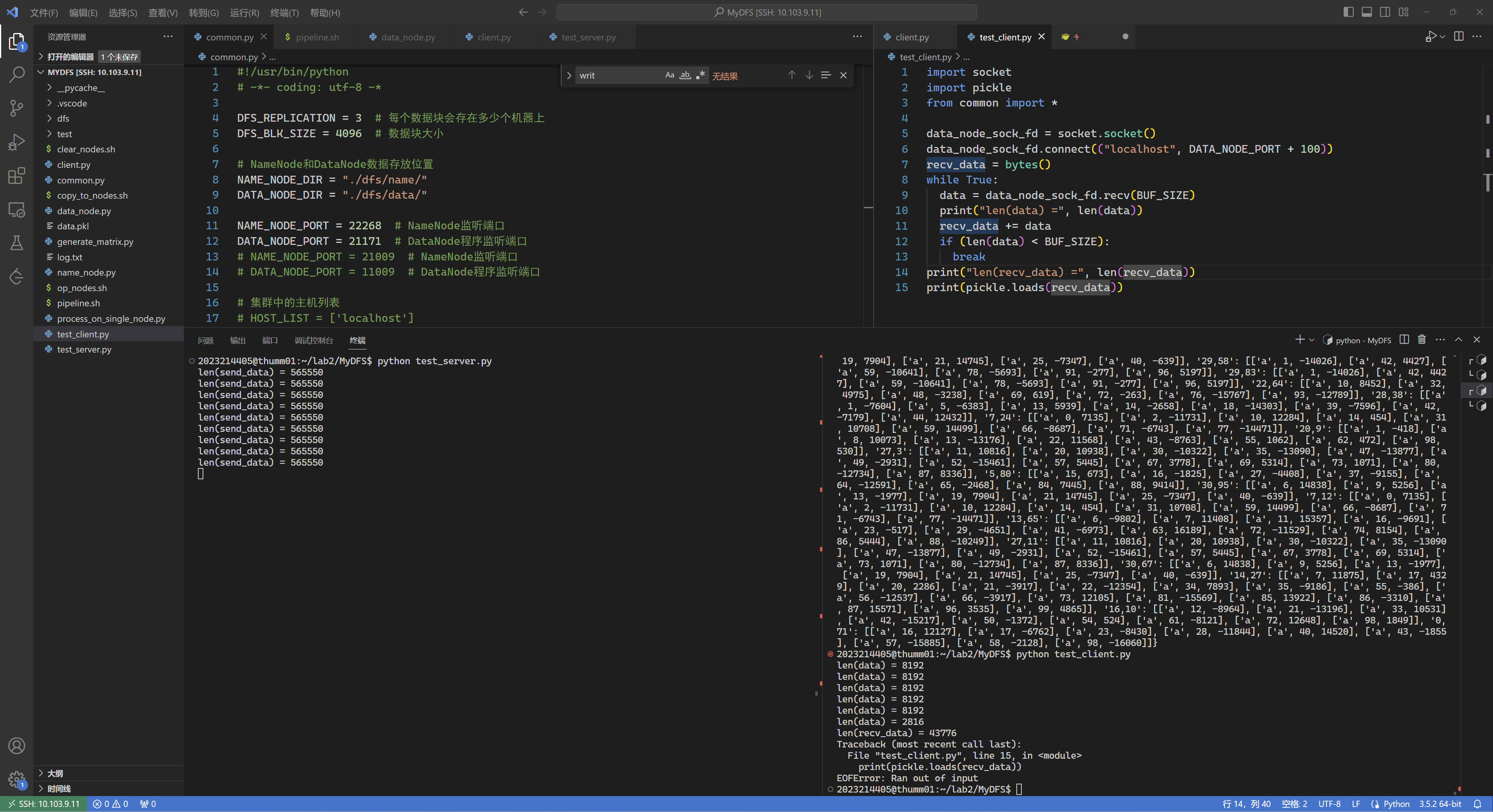
网上很多方法 在传输大文件时会遇到问题,会报错:EOFError: Ran out of input。如下图所示,发送方发送的数据长度是565550,接收方时而能接受到完整数据,比如右下方终端窗中上一次运行中恢复出了recv_data;时而失败,比如右下终端窗中这一次运行失败,只接收到了43776字节。
比较神奇的是每次运行失败都是接受到固定字节数的数据,test_client.py中是43776字节,client.py中是14480字节,本人求助谷歌后没有获得有效的线索。
这里采取的解决方法是在使用json.dumps对object进行序列化后,在前面使用4字节的字段保存长度。
为了偷懒,程序中只用涉及传输列表、字典等高级对象时才使用 send_obj 和 receive_obj, 传输字符串部分的代码不改了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import structimport jsondef send_msg (conn, msg ): conn.sendall(struct.pack('I' , len (msg)) + msg) def send_obj (conn, msg ): send_msg(conn, json.dumps(msg).encode()) def receive_msg (conn ): msg_len = struct.unpack('I' , conn.recv(4 ))[0 ] ret = b'' while len (ret) < msg_len: msg = conn.recv(msg_len - len (ret)) if msg is None : return None ret = ret + msg return ret def receive_obj (conn ): return json.loads(receive_msg(conn).decode())
client.py 发布Map任务,执行Reduce任务
MapReduce编程模型中Map和Reduce的抽象输入输出如下所示:
1 2 map(k1,v1) ->list(k2,v2) reduce(k2,list(v2)) ->list(v2)
client 在 MapReduce 函数中实现发布Map任务,执行Reduce任务的功能,可分为以下几步
CopyFromLocal
分配Map任务, DataNode作为Mapper生成list(k: v)并返回
执行Reduce
整理得到输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 def MapReduce (self, m, p, n, input_file, output_file ): blk_size_list = self.preCalculateFileSize(input_file) request = "new_fat_item {} " .format (input_file) print ("Request: {}" .format (request)) self.name_node_sock.send(bytes (request, encoding='utf-8' )) time.sleep(0.2 ) send_obj(self.name_node_sock, blk_size_list) fat_pd = self.name_node_sock.recv(BUF_SIZE) fat_pd = str (fat_pd, encoding='utf-8' ) print ("Fat: \n{}" .format (fat_pd)) fat = pd.read_csv(StringIO(fat_pd)) fp = open (input_file) for idx, row in fat.iterrows(): data = fp.read(int (row['blk_size' ])) datanode_hosts = re.findall(r"'(.+?)'" , row['host_name' ]) for host in datanode_hosts: data_node_sock = socket.socket() data_node_sock.connect((host, DATA_NODE_PORT)) blk_path = input_file + ".blk{}" .format (row['blk_no' ]) request = "store {}" .format (blk_path) data_node_sock.send(bytes (request, encoding='utf-8' )) time.sleep(0.2 ) data_node_sock.send(bytes (data, encoding='utf-8' )) data_node_sock.close() fp.close() print ("Finish CopyFromLocal" ) key_valuelist = dict () fat = pd.read_csv(StringIO(fat_pd)) for idx, row in fat.iterrows(): datanode_hosts = re.findall(r"'(.+?)'" , row['host_name' ]) data_node_sock = socket.socket() data_node_sock.connect((datanode_hosts[0 ], DATA_NODE_PORT)) blk_path = input_file + ".blk{}" .format (row['blk_no' ]) request = "map {} {} {}" .format (blk_path, m, n) data_node_sock.send(bytes (request, encoding='utf-8' )) key_values = receive_obj(data_node_sock) for k in key_values.keys(): if k not in key_valuelist.keys(): key_valuelist[k] = key_values[k] else : key_valuelist[k] += key_values[k] print ("Finish Reduce" ) ij_matrix = dict () for key, valuelist in key_valuelist.items(): a_idx_val = {} b_idx_val = {} for mat_idx_val in valuelist: mat, idx, val = mat_idx_val[0 ], mat_idx_val[1 ], mat_idx_val[2 ] if (mat == 'a' ): a_idx_val[idx] = val else : b_idx_val[idx] = val res_element_val = 0 for idx in a_idx_val.keys(): if idx in b_idx_val.keys(): res_element_val += a_idx_val[idx] * b_idx_val[idx] if res_element_val != 0 : ij_matrix[key] = res_element_val with open (output_file, "w" ) as of: for ij in sorted (ij_matrix, key=lambda ij: [int (x) for x in ij.split(',' )]): of.write("{},{}\n" .format (ij, ij_matrix[ij])) print ("Finish writing to output file." )
将来自不同Mapper的 k : list(v) 合并时,合并的是list,使用的是 +=。
按键数值排序规则可以这样写:for ij in sorted(ij_matrix, key=lambda ij: [int(x) for x in ij.split(',')])。
data_node.py中map函数
dict 不支持相同key不同value的数据,由于我们的最终的目的是要得到 k : list(v),这里干脆不先生成list(k : v),直接生成 k : list(v) 好了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def map (self, dfs_path, m, n ): local_path = os.path.join(DATA_NODE_DIR, dfs_path) key_valuelist = dict () for line in open (local_path): line_4parts = line.split(',' ) mat, i, j, val = line_4parts[0 ], int (line_4parts[1 ]), int (line_4parts[2 ]), int (line_4parts[3 ]) if mat == 'A' : for k in range (1 , n + 1 ): str_i_k = "{},{}" .format (i, k) if str_i_k not in key_valuelist.keys(): key_valuelist[str_i_k] = [['a' , j, val]] else : key_valuelist[str_i_k].append(['a' , j, val]) elif mat == 'B' : for k in range (1 , m + 1 ): str_k_j = "{},{}" .format (k, j) if str_k_j not in key_valuelist.keys(): key_valuelist[str_k_j] = [['b' , i, val]] else : key_valuelist[str_k_j].append(['b' , i, val]) return key_valuelist
list 类型的[i, k]不可哈希,可以将其格式化成字符串作为key。
生成k : list(v) 时,当遇到相同k时,将v纳入结果list时使用的操作是append。
测试验证
Example上的验证
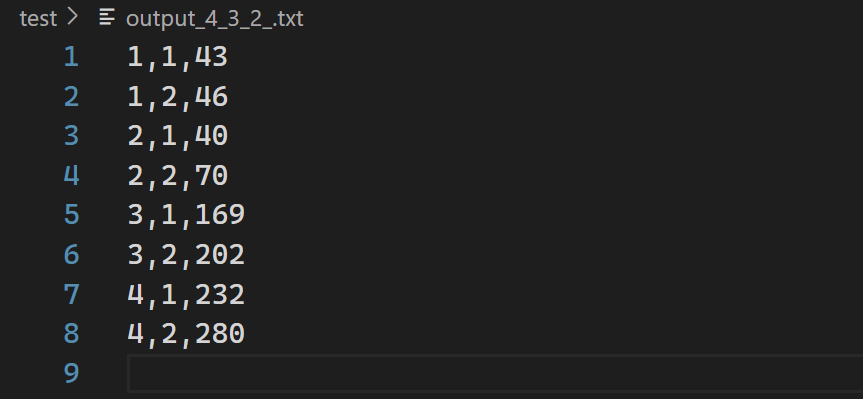
1 2 3 4 5 6 7 8 9 10 xxxxxxxxxx@thumm01:~/lab2/MyDFS$ python client.py -MapReduce test /input_4_3_2_.txt test /output_4_3_2_.txt 4 test /output_4_3_2_.txt Request: new_fat_item test /input_4_3_2_.txt Fat: blk_no,host_name,blk_size 0,['thumm01' 'thumm03' 'thumm05' ],133 Finish CopyFromLocal Finish Reduce Finish writing to output file.
随机数组上的验证
generate_matrix.py: 生成随机数组并以稀疏矩形式保存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import numpy as npdef reslove_as_sparse_matrix (which_mat, mat, f ): print (which_mat, mat.shape[0 ], mat.shape[1 ]) n1, n2 = mat.shape[0 ], mat.shape[1 ] for i in range (n1): for j in range (n2): if (mat[i][j] != 0 ): f.write("{},{},{},{}\n" .format (which_mat, i + 1 , j + 1 , mat[i][j])) m_p_n = np.random.randint(low=100 , high=200 , size=3 ) print (m_p_n)m, p, n = m_p_n[0 ], m_p_n[1 ], m_p_n[2 ] with open ("test/input_{}_{}_{}_.txt" .format (m, p, n), "w" ) as f: mask_A = np.where(np.random.rand(m, p) < 0.1 , 1 , 0 ) mat_A = np.random.randint(-0x3f3f , 0x3f3f , (m, p)) mat_A = mask_A * mat_A reslove_as_sparse_matrix('A' , mat_A, f) mask_B = np.where(np.random.rand(p, n) < 0.1 , 1 , 0 ) mat_B = np.random.randint(-0x3f3f , 0x3f3f , (p, n)) mat_B = mask_B * mat_B reslove_as_sparse_matrix('B' , mat_B, f)
process_on_single_node.py: 单机矩阵乘法验证
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import sysimport numpy as npargv = sys.argv argc = len (argv) - 1 input_file = argv[1 ] input_file_parts = input_file.split('_' ) m, p, n = int (input_file_parts[1 ]), int (input_file_parts[2 ]), int (input_file_parts[3 ]) mat_A, mat_B = np.zeros((m, p), dtype=int ), np.zeros((p, n), dtype=int ) for line in open (input_file): line_4_parts = line.split(',' ) which_mat, i, j, val = line_4_parts[0 ], int (line_4_parts[1 ]), int (line_4_parts[2 ]), int (line_4_parts[3 ]) if which_mat == 'A' : mat_A[i - 1 ][j - 1 ] = val elif which_mat == 'B' : mat_B[i - 1 ][j - 1 ] = val mat_C = mat_A.dot(mat_B) n1, n2 = mat_C.shape[0 ], mat_C.shape[1 ] with open ("test/output_single_{}_{}_{}_.txt" .format (m, p, n), "w" ) as f: for i in range (n1): for j in range (n2): if (mat_C[i][j] != 0 ): f.write("{},{},{}\n" .format (i + 1 , j + 1 , mat_C[i][j]))
对比
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 xxxxxxxxxx@thumm01:~/lab2/MyDFS$ python client.py -MapReduce test /input_111_182_134_.txt test /output_111_182_134_.txt 165 test /output_165_147_144_.txt Request: new_fat_item test /input_165_147_144_.txt Fat: blk_no,host_name,blk_size 0,['thumm06' 'thumm05' 'thumm04' ],4089 1,['thumm06' 'thumm01' 'thumm05' ],4085 2,['thumm05' 'thumm03' 'thumm04' ],4092 3,['thumm05' 'thumm06' 'thumm04' ],4089 4,['thumm03' 'thumm04' 'thumm01' ],4095 5,['thumm05' 'thumm03' 'thumm04' ],4087 6,['thumm05' 'thumm06' 'thumm03' ],4096 7,['thumm01' 'thumm03' 'thumm06' ],4092 8,['thumm01' 'thumm04' 'thumm03' ],4091 9,['thumm04' 'thumm06' 'thumm01' ],4087 10,['thumm06' 'thumm01' 'thumm04' ],4091 11,['thumm05' 'thumm03' 'thumm04' ],4085 12,['thumm05' 'thumm06' 'thumm01' ],4085 13,['thumm01' 'thumm04' 'thumm06' ],4091 14,['thumm01' 'thumm04' 'thumm06' ],4096 15,['thumm01' 'thumm06' 'thumm04' ],3286 Finish CopyFromLocal Finish Reduce Finish writing to output file. xxxxxxxxxx@thumm01:~/lab2/MyDFS$ python process_on_single_node.py test /input_111_182_134_.txt
如图所示,结果一致。
Bonus
Q:请对比一下单机处理矩阵乘法以及你自己设计的 mapreduce 矩阵乘法的时间性能,并解释为什么
使用time对比时间性能如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 xxxxxxxxxx@thumm01:~/lab2/MyDFS$ time python client.py -MapReduce test /input_111_182_134_.txt test /output_111_182_134_.txt 111 test /output_111_182_134_.txt Request: new_fat_item test /input_111_182_134_.txt Fat: blk_no,host_name,blk_size 0,['thumm06' 'thumm01' 'thumm03' ],4087 1,['thumm03' 'thumm05' 'thumm06' ],4094 2,['thumm01' 'thumm05' 'thumm03' ],4090 3,['thumm06' 'thumm04' 'thumm01' ],4091 4,['thumm05' 'thumm04' 'thumm03' ],4084 5,['thumm06' 'thumm05' 'thumm03' ],4085 6,['thumm01' 'thumm04' 'thumm06' ],4087 7,['thumm01' 'thumm04' 'thumm03' ],4094 8,['thumm01' 'thumm03' 'thumm06' ],4086 9,['thumm06' 'thumm03' 'thumm05' ],4090 10,['thumm04' 'thumm03' 'thumm05' ],4089 11,['thumm04' 'thumm05' 'thumm03' ],4091 12,['thumm06' 'thumm01' 'thumm04' ],4093 13,['thumm04' 'thumm06' 'thumm01' ],4092 14,['thumm01' 'thumm06' 'thumm03' ],4090 15,['thumm04' 'thumm05' 'thumm03' ],2781 Finish CopyFromLocal Finish Reduce Finish writing to output file. real 0m16.871s user 0m2.780s sys 0m0.988s xxxxxxxxxx@thumm01:~/lab2/MyDFS$ time python process_on_single_node.py test /input_111_182_134_.txt real 0m0.259s user 0m0.692s sys 0m0.768s
可以看到MapReduce几乎是单机程序的60倍左右,出现这种问题的原因是,虽然Map在多机上运行能通过并行提高效率,但是与name_node和data_node的网络通信才是性能瓶颈。
本实验中中MapReduce和单机程序还有许多可以优化的地方。矩阵分块 技术写出缓存友好的代码,可以使用多线程CPU和GP计算矩阵乘法。