xxxxxxxxxx@thumm01:~$ bash auto_autho.sh /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/dsjxtjc/xxxxxxxxxx/.ssh/id_rsa.pub" /usr/bin/ssh-copy-id: INFO: attempting to login with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: WARNING: All keys were skipped because they already exist on the remote system. (if you think this is a mistake, you may want to use -f option)
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/dsjxtjc/xxxxxxxxxx/.ssh/id_rsa.pub" /usr/bin/ssh-copy-id: INFO: attempting to login with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: WARNING: All keys were skipped because they already exist on the remote system. (if you think this is a mistake, you may want to use -f option)
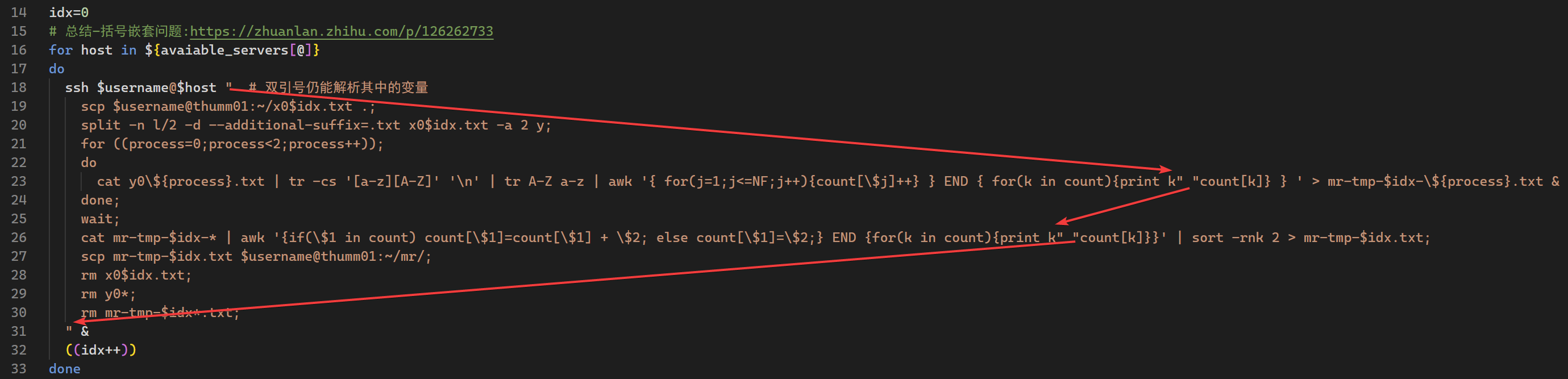
split -n l/10 -d --additional-suffix=.txt wc_dataset.txt -a 2 x while (( $(ls -l generated_dataset.txt | awk '{print $5}') < $target_size )) do cat x0$(( $RANDOM % 10)).txt >> generated_dataset.txt done
rm x*
split 用法
1 2 3 4 5 6 7 8
split -n l/10 -d --additional-suffix=.txt wc_dataset.txt -a 2 x split [OPTION]... [FILE [PREFIX]] -l, --lines=NUMBER put NUMBER lines/records per output file l/N split into N files without splitting lines/records -d use numeric suffixes starting at 0, not alphabetic -a, --suffix-length=N generate suffixes of length N (default 2)
tr -cs "[a-z][A-Z]""\n"# 将非大小写字母都转化为换行符 -c, -C, --complement use the complement of SET1 # complement: 补集 -s, --squeeze-repeats replace each sequence of a repeated character that is listed in the last specified SET, with a single occurrence of that character # Translation occurs if -d is not given and both SET1 and SET2 appear. # -d表示删除
sort 用法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
sort -rnk2 # 根据第2个字段的数字大小进行逆序排序 -r, --reverse reverse the result of comparisons -n, --numeric-sort compare according to string numerical value -k, --key=KEYDEF sort via a key; KEYDEF gives location and type KEYDEF is F[.C][OPTS][,F[.C][OPTS]] for start and stop position, where F is a field number and C a character position in the field; both are origin 1, and the stop po‐ sition defaults to the line's end. If neither -t nor -b is in effect, characters in a field are counted from the beginning of the preceding whitespace. OPTS is one or more single-letter ordering options [bdfgiMhnRrV], which override global ordering options for that key. If no key is given, use the entire line as the key. Use --debug to diagnose incorrect key usage.