
6.5840 2023 Lecture 5 Raft (1)
课程网址:https://pdos.csail.mit.edu/6.824/schedule.html
以下内容来自课程课件,由于课件纯文本显示效果不佳,故对其排版整理并添加了部分个人笔记批注。
Raft是分布式复制协议的核心组件之一,实现完全自动化和容错都必须的
前面介绍过的复制系统,都存在单点故障问题(single point of failure)
- mapreduce中的cordinator
- GFS的master
- VM-FT的test-and-set存储服务器storag
- 诸如Raft一类的协议用于解决单点故障问题,同时也用于解决网络分区问题。这类解决方案的基本思想即:大多数原则(majority rule)
- 可以据此构建容错服务,也可以处理网络分区,并在服务器故障中表现出很强的一致性
另一个考虑大多数的方式是,即使发生网络分区,也只会有一个拥有多数的分区,只有拥有多数的分区才能继续进行
- 人们都是用raft来构建一个复制状态机
- 操作提交对追随者来说是透明的
- term id唯一地表示 领导者附加日志条目,一个任期内只有一个领导者
- 不会有两个日志条目具有相同的idx,相同的任期和不同的命令,因为在特定期内只会有一个领导者,领导者只会使用追加(append)操作。
- 为了确保follower记得投票给了哪位候选人,并永远不会改变注意,follower必须把投票结果记录到stable storage中
- 必须要按照figure2说明来做,但是它也有些细节缺失,比如如何回应rpc
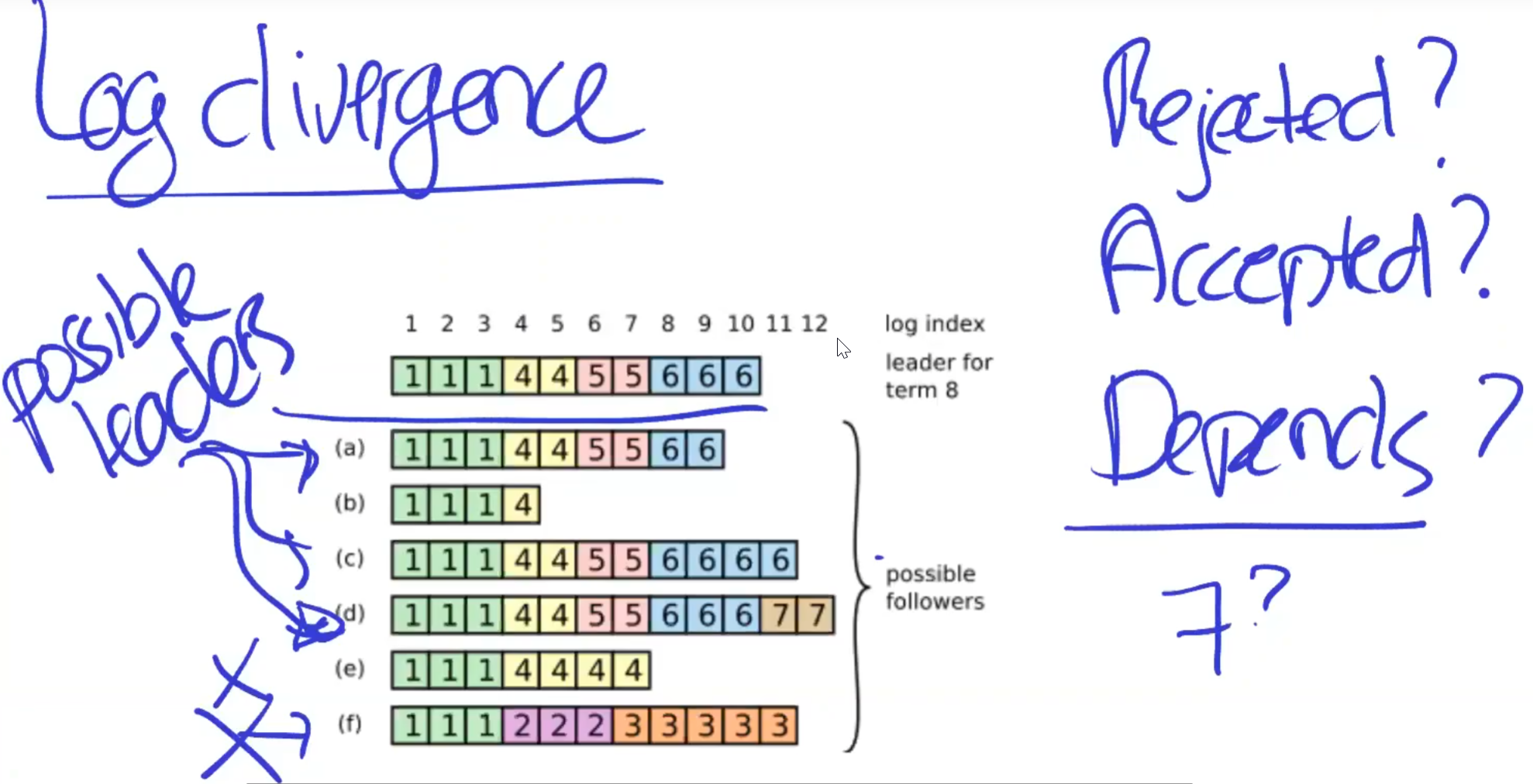
d一定是term7的leader
而在term8中,当a需要投票时,d仅仅只是投拒绝,而不能强制组织a称为leader
https://thesquareplanet.com/blog/students-guide-to-raft/
https://thesquareplanet.com/blog/raft-qa/
https://blog.josejg.com/debugging-pretty/
nextIndex是乐观的,使用nextIndex而非一次发送所有日志就是为了减少带宽
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 徒心的网络自留地!
相关推荐
评论