6.5840 2023 Lecture 3 GFS
课程网址:https://pdos.csail.mit.edu/6.824/schedule.html
以下内容来自课程课件,由于课件纯文本显示效果不佳,故对其排版整理并添加了部分个人笔记批注。
Today’s topic: storage + gfs + consistency
Why hard?
high performance -> shared data across servers
many servers -> constant faults
fault tolerance -> replication
replication -> potential inconsistencies
storge consistencies -> lower performance
Ideal consistency: behave as if single system
有两种风险: concurrency 和 fault
Why storage system is important?
建造fault tolerant存储系统后,应用程序可以是无状态的,存储系统存储持久化状态。
GFS context
- Many Google services needed a big fast unified storage system
Mapreduce, crawler, indexer, log storage/analysis - Shared among multiple applications e.g. crawl, index, analyze
- Huge capacity
- Huge performance
- Fault tolerant
- But:
- just for internal Google use
- aimed at batch big-data performance, not interactive
Google使用过GFS,后面提出的Colossus、以及其他类型的基于集群的文件系统比如MapReduce使用的HDFS的灵感都来源于GFS
在GFS之前的设计都不规范,这种不规范性来源于两方面:
- 只有1个master,master不可复制——构建出的容错文件系统却包含单点故障
- inconsistencies
即使今天,在容错、复制、性能和一致性之间都存在着斗争
GFS overview
- 100s/1000s of clients (e.g. MapReduce worker machines)
- 100s of chunkservers, each with its own disk
- one coordinator
Capacity story?
- big files split into 64 MB chunks
- each file’s chunks striped/sharded over chunkservers
so a file can be much larger than any one disk - each chunk in a Linux file
stripe: n.条纹,线条;(军装上表示等级的)臂章,军阶条;类型,特点; v.给……加条纹
sharded: adj.分片的
Throughput story?
- clients talk directly to chunkservers to read/write data
- if lots of clients access different chunks, huge parallel throughput read or write
Fault tolerance story?
- each 64 MB chunk stored (replicated) on three chunkservers
- client writes are sent to all of a chunk’s copies
- a read just needs to consult one copy
GFS并非完全自动容错,但在提高容错能力方面做的相当好
What are the steps when client C wants to read a file?
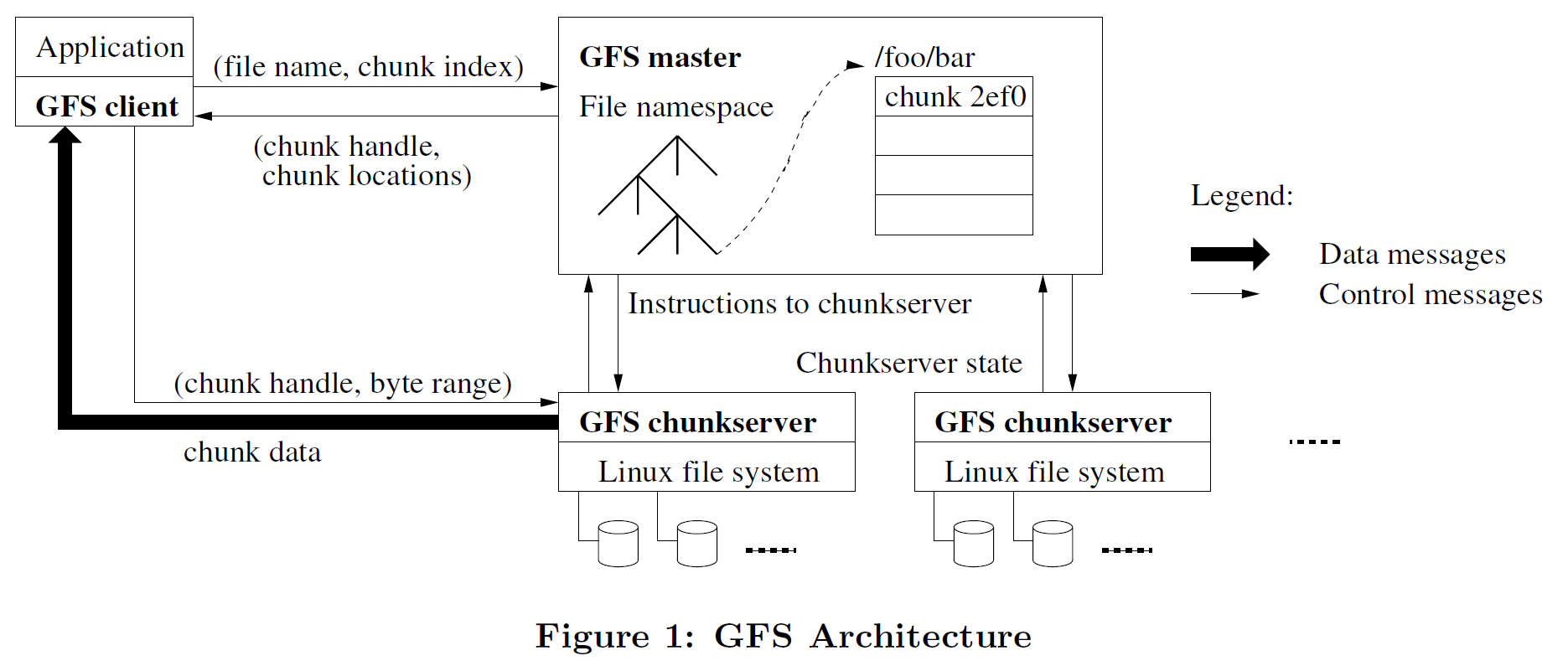
- C sends filename and offset to coordinator (CO) (if not cached)
CO has a filename -> array-of-chunkhandle table
and a chunkhandle -> list-of-chunkservers table - CO finds chunk handle for that offset
- CO replies with chunkhandle + list of chunkservers
- C caches handle + chunkserver list
- C sends request to nearest chunkserver
chunk handle, offset - chunk server reads from chunk file on disk, returns to client
第4步中client缓存的目的:减少延迟 + 减少与master的通信,提高CO的throughput:缓存后当需要想通块时不需要向CO询问
Clients only ask coordinator where to find a file’s chunks
- clients cache name -> chunkhandle info
- coordinator does not handle data, so (hopefully) not heavily loaded
master的状态维护:
- file name -> array of chunk handles
放在stable storage中:如果master crash,重启后从日志中重建- chunk handle -> version# && list of chunk servers (primary, ?secondaries?) 每个主服务器有一个释放时间
除了version外可放进内存中
version需要放进stable storage中,它需要知道chunk server的块是否是旧的。为什么不能是master向所有chunk server去要信息,然后找到最大版本号的那个作为最新块:有可能崩溃丢失的块才是最新块- log + checkpoints
每当名称空间发生更改时,需要把log写入stable storage
在回应客户端之前,改变使master首先写入稳定存储器,然后对客户端回应
master的checkpoints也需要写入stable storage
计划:storage gfs consistency
Ideal consistency: behave as if single system
有两种风险: concurrency 和 fault
GFS: performance -> replication + FT -> consistency
GFS依然在2方面不规范:1、只有一个master,无法复制(包含单点故障);2、in-consistencies,不具备强一致性,容错、复制、性能、一致性之间的斗争至今仍存在
GFS 的关键属性:
- Big: large data set,比如MapReduce的数据集可能是整个万维网
- Fast: the way is to do automatic sharding
- Global: all apps see the same fs
- Fault tolerant: 并不会完全自动容错,但在提高容错能力方面做的相当好
master的状态维护:
- file name -> array of chunk handles
放在stable storage中:如果master crash,重启后从日志中重建 - chunk handle -> version# && list of chunk servers (primary, ?secondaries?) 每个主服务器有一个释放时间
除了version外可放进内存中
version需要放进stable storage中,它需要知道chunk server的块是否是旧的。为什么不能是master向所有chunk server去要信息,然后找到最大版本号的那个作为最新块:有可能崩溃丢失的块才是最新块 - log + checkpoints
每当名称空间发生更改时,需要把log写入stable storage
在回应客户端之前,改变使master首先写入稳定存储器,然后对客户端回应
master的checkpoints也需要写入stable storage
Write a file: append
filename -> chunk handles
handles->servers:
- increase #ver
master和chunk servers都把版本号放在stabel storage上 - primiary + secondary
- lease
append时,检查#ver是否有效 + lease是否有效
如果primary向secondary B写入失败时,会重写,重写时使用不同的offset
GFS只在google内部使用,所有节点都(认为)是可信的
版本号由coordinator维护,并且仅在选取新的coordinator时才会增加
序列号和版本号不同
当考虑consistency时,需要考虑所有可能的失败,并讨论这些失败是否会导致不一致
如果master向primary发送心跳包得不到回应,也只能等到lease到期时才能选取新的primary,否则可能会有2个primary
split brain syndrome 脑裂:产生两个primary
解决的方法就是使用lease,只有当lease expired时才选取新的primary
获得更强的一致性:Update all P + s or none
GFS是针对MapReduce定制的?