6.5840 2023 Lecture 1 Introduction
课程网址:https://pdos.csail.mit.edu/6.824/schedule.html
以下内容来自课程课件,由于课件纯文本显示效果不佳,故对其排版整理并添加了部分个人笔记批注。
6.5840: Distributed Systems Engineering
What I mean by “distributed system”:
- a group of computers cooperating to provide a service
this class is mostly about infrastructure services
e.g. storage for big web sites, MapReduce, peer-to-peer sharing - lots of important infrastructure is distributed
Why do people build distributed systems?
- to increase capacity via parallel processing
- to tolerate faults via replication
- to match distribution of physical devices e.g. sensors
- to increase security via isolation
But it’s not easy:
- concurrency
- complex interactions
- partial failure
- hard to get high performance
Why study this topic?
- interesting – hard problems, powerful solutions
- widely used – driven by the rise of big Web sites
- active research area – important unsolved problems
- challenging to build – you’ll do it in the labs
COURSE STRUCTURE
Course components:
lectures、papers、two exams、labs、final project (optional)
Lectures:
big ideas, paper discussion, lab guidance
will be recorded, available online
Papers:
there’s a paper assigned for almost every lecture
research papers, some classic, some new
problems, ideas, implementation details, evaluation
please read papers before class!
web site has a short question for you to answer about each paper
and we ask you to send us a question you have about the paper
submit answer and question before start of lecture
Exams:
Mid-term exam in class
Final exam during finals week
Mostly about papers and labs
Labs:
goal: deeper understanding of some important ideas
goal: experience with distributed programming
first lab is due a week from Friday
one per week after that for a while
Lab 1: distributed big-data framework (like MapReduce)
Lab 2: fault tolerance using replication (Raft)
Lab 3: a simple fault-tolerant database
Lab 4: scalable database performance via sharding
Optional final project at the end, in groups of 2 or 3.
The final project substitutes for Lab 4.
You think of a project and clear it with us.
Code, short write-up, demo on last day.
MAIN TOPICS
This is a course about infrastructure for applications.
-
Storage.
-
Communication.
-
Computation.
A big goal: hide the complexity of distribution from applications.
Topic: fault tolerance
- 1000s of servers, big network -> always something broken
We’d like to hide these failures from the application.
“High availability”: service continues despite failures - Big idea: replicated servers.
If one server crashes, can proceed using the other(s).
Labs 2 and 3
Topic: consistency
- General-purpose infrastructure needs well-defined behavior.
E.g. “Get(key) yields the value from the most recent Put(key,value).” - Achieving good behavior is hard!
e.g. “Replica” servers are hard to keep identical.
Topic: performance
- The goal: scalable throughput
Nx servers -> Nx total throughput via parallel CPU, RAM, disk, net. - Scaling gets harder as N grows:
Load imbalance.
Slowest-of-N latency.
Some things don’t speed up with N: initialization, interaction.
Labs 1, 4
Topic: tradeoffs
- Fault-tolerance, consistency, and performance are enemies.
Fault tolerance and consistency require communication
e.g., send data to backup server
e.g., check if cached data is up-to-date
communication is often slow and non-scalable - Many designs provide only weak consistency, to gain speed.
e.g. Get() might not yield the latest Put()!
Painful for application programmers but may be a good trade-off.
We’ll see many design points in the consistency/performance spectrum.
Topic: implementation
RPC, threads, concurrency control, configuration.
The labs…
CASE STUDY: MapReduce
Let’s talk about MapReduce (MR)
- a good illustration of 6.5840’s main topics
- hugely influential
- the focus of Lab 1
MapReduce overview
- context: multi-hour computations on multi-terabyte data-sets
e.g. build search index, or sort, or analyze structure of web
only practical with 1000s of computers
applications not written by distributed systems experts - big goal: easy for non-specialist programmers
programmer just defines Map and Reduce functions
often fairly simple sequential code - MR manages, and hides, all aspects of distribution!
multi-hour是什么意思?
MapReduce不适合1000以上规模的集群吗?
Abstract view of a MapReduce job – word count
1 | Input1 -> Map -> a,1 b,1 |
- input is (already) split into M files
- MR calls Map() for each input file, produces list of k,v pairs
“intermediate” data
each Map() call is a “task” - when Maps are done,
MR gathers all intermediate v’s for each k,
and passes each key + values to a Reduce call - final output is set of <k,v> pairs from Reduce()s
Word-count-specific code
- Map(k, v)
split v into words
for each word w
emit(w, “1”) - Reduce(k, v_list)
emit(len(v_list))
MapReduce scales well:
- N “worker” computers (might) get you Nx throughput.
Maps()s can run in parallel, since they don’t interact.
Same for Reduce()s. - Thus more computers -> more throughput – very nice!
MapReduce hides many details:
- sending app code to servers
- tracking which tasks have finished
- “shuffling” intermediate data from Maps to Reduces
- balancing load over servers
- recovering from failures
However, MapReduce limits what apps can do:
- No interaction or state (other than via intermediate output).
- No iteration
- No real-time or streaming processing.
Some details (paper’s Figure 1)
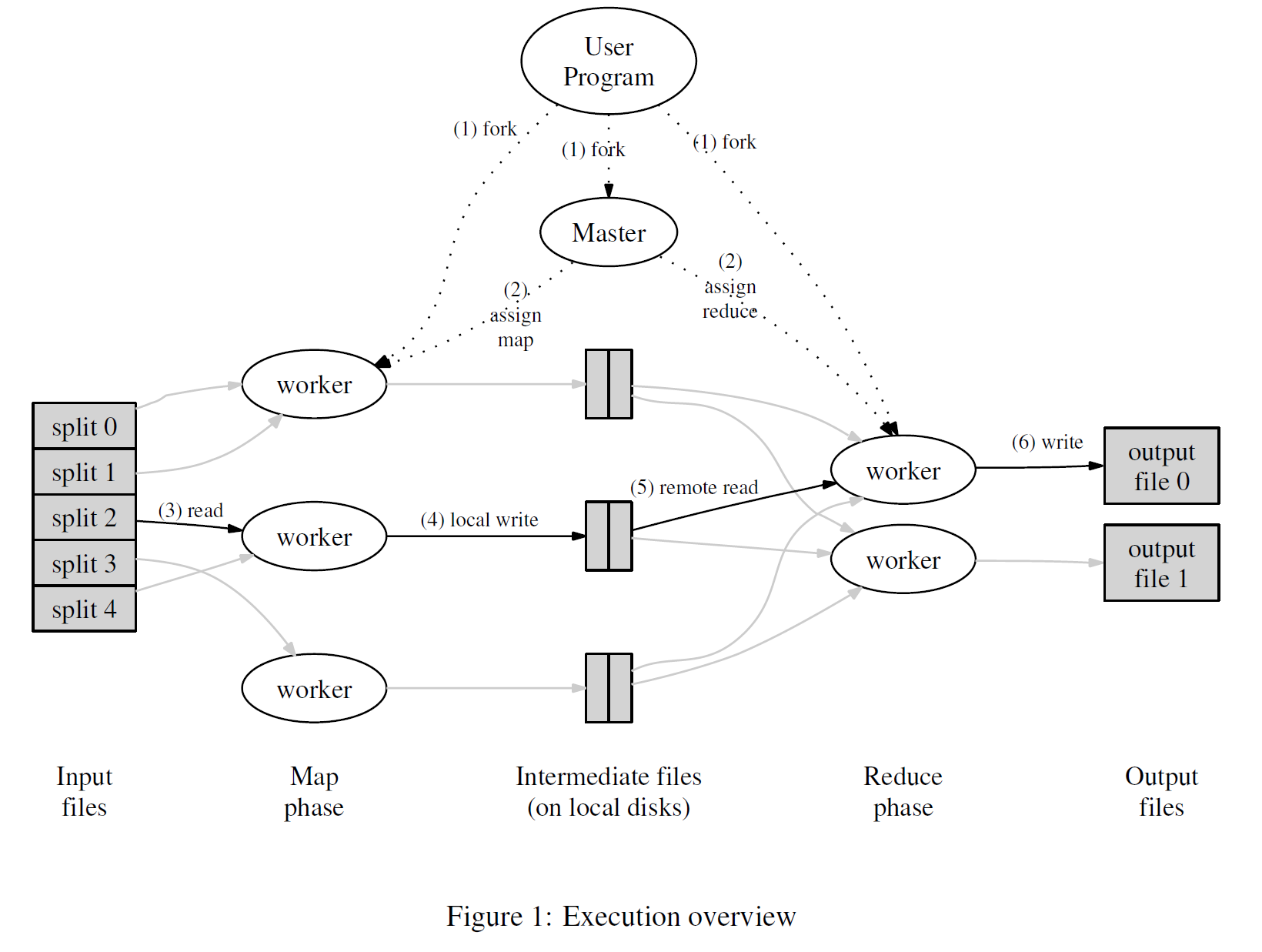
Input and output are stored on the GFS cluster file system
- MR needs huge parallel input and output throughput.
- GFS splits files over many servers, in 64 MB chunks
Maps read in parallel
Reduces write in parallel - GFS also replicates each file on 2 or 3 servers
- GFS is a big win for MapReduce
The “Coordinator” manages all the steps in a job.
- coordinator gives Map tasks to workers until all Maps complete
Maps write output (intermediate data) to local disk
Maps split output, by hash(key) mod R, into one file per Reduce task - after all Maps have finished, coordinator hands out Reduce tasks
each Reduce task corresponds to one hash bucket of intermediate output
each Reduce fetches its intermediate output from (all) Map workers
each Reduce task writes a separate output file on GFS
What will likely limit the performance?
We care since that’s the thing to optimize.
CPU? memory? disk? network?
- In 2004 authors were limited by network capacity.
What does MR send over the network?
Maps read input from GFS.
Reduces read Map intermediate output.
Often as large as input, e.g. for sorting.
Reduces write output files to GFS.
[diagram: servers, tree of network switches] - In MR’s all-to-all shuffle, half of traffic goes through root switch.
Paper’s root switch: 100 to 200 gigabits/second, total
1800 machines, so 55 megabits/second/machine.
55 is small: much less than disk or RAM speed.
How does MR minimize network use?
- Coordinator tries to run each Map task on GFS server that stores its input.
All computers run both GFS and MR workers
So input is read from local disk (via GFS), not over network. - Intermediate data goes over network just once.
Map worker writes to local disk.
Reduce workers read from Map worker disks over the network.
Storing it in GFS would require at least two trips over the network. - Intermediate data partitioned into files holding many keys.
R is much smaller than the number of keys.
Big network transfers are more efficient.
How does MR get good load balance?
- Wasteful and slow if N-1 servers have to wait for 1 slow server to finish.
- But some tasks likely take longer than others.
- Solution: many more tasks than worker machines.
Coordinator hands out new tasks to workers who finish previous tasks.
No task is so big it dominates completion time (hopefully).
So faster servers do more tasks than slower ones,
And all finish at about the same time.
What about fault tolerance?
What if a worker crashes during a MR job?
We want to hide failures from the application programmer!
Does MR have to re-run the whole job from the beginning?
Why not?
MR re-runs just the failed Map()s and Reduce()s.
Suppose MR runs a Map twice, one Reduce sees first run’s output, but another Reduce sees the second run’s output?
Could the two Reduces produce inconsistent results?
- No: Map() must produce exactly the same result if run twice with same input.
And Reduce() too. - So Map and Reduce must be pure deterministic functions:
they are only allowed to look at their arguments/input.
no state, no file I/O, no interaction, no external communication.
Details of worker crash recovery:
- a Map worker crashes:
coordinator notices worker no longer responds to pings
coordinator knows which Map tasks ran on that worker
those tasks’ intermediate output is now lost, must be re-created
coordinator tells other workers to run those tasks
can omit re-running if all Reduces have fetched the intermediate data - a Reduce worker crashes:
finished tasks are OK – stored in GFS, with replicas.
coordinator re-starts worker’s unfinished tasks on other workers.
Other failures/problems:
- What if the coordinator gives two workers the same Map() task?
perhaps the coordinator incorrectly thinks one worker died.
it will tell Reduce workers about only one of them. - What if the coordinator gives two workers the same Reduce() task?
they will both try to write the same output file on GFS!
atomic GFS rename prevents mixing; one complete file will be visible. - What if a single worker is very slow – a “straggler”?
perhaps due to flakey hardware.
coordinator starts a second copy of last few tasks. - What if a worker computes incorrect output, due to broken h/w or s/w?
too bad! MR assumes “fail-stop” CPUs and software. - What if the coordinator crashes?
正常情况下,coordinator(master)就不会给两个workers相同的Map()任务吗?
只有超时时才会把该任务分发给新worker吗?flakey(易出故障的;不可靠的(等于 flaky)
h/w or s/w 是什么?
Current status?
Hugely influential (Hadoop, Spark, &c).
Probably no longer in use at Google.
Replaced by Flume / FlumeJava (see paper by Chambers et al).
GFS replaced by Colossus (no good description), and BigTable.
Conclusion
MapReduce made big cluster computation popular.
- -Not the most efficient or flexible.
- +Scales well.
- +Easy to program – failures and data movement are hidden.
These were good trade-offs in practice.
We’ll see some more advanced successors later in the course.
Have fun with Lab 1!